


Creating a Reproducible BI and Analytics Stack That Just Works Anywhere with Flox
This article demonstrates using Flox, built on Nix, to create portable, reproducible environments for data work.
It provides a local PostgreSQL database paired with Metabase—an open-source BI and analytics platform—using a real-world public retail dataset. It’s the kind of thing you might put into a container for data scientists, data analysts, or other practitioners.
Except this runtime isn’t built into a container—or a VM. It runs directly on your local system.
This environment serves as a proof of concept. Because before you can ship a reproducible BI and analytic runtime to downstream users, you have to build it—model your data, debug your ETL, test your queries, make sure it runs locally. In a nutshell, reproducibility at runtime depends on reproducibility at dev-time.
Read on to learn how Flox enables you to create and share portable, reproducible dev environments for data!
Reproducibility crisis
Shipping a reproducible runtime for BI and analytics isn’t all that difficult. It’s why we have containers, VMs, and bare-metal Flox/Nix environments. The difficult part involves iterating quickly and predictably on your local system as you build, test, and debug the environment. That work has to happen before you bake it into a runtime artifact. This dev-time reproducibility is the prerequisite for runtime reproducibility: if it runs and behaves the same anywhere in local dev, it will run and behave the same in prod, too.
This article shows you how you can bootstrap an environment for BI and analytics and start building right away—without containers, without installing software system-wide (or in $HOME), and without worrying about dependency conflicts, relict systemd or launchd services, or global changes to your system. To rm -rf your project repo is to completely purge this environment from your system.
More to the point, it also demonstrates why dev-time reproducibility matters. Building out a real ETL pipeline, creating and refactoring a star schema, or debugging against real-world data in a production-grade database is the kind of iterative, run-and-debug work that grinds to a halt if your environment isn’t reproducible.
Let’s get down to the nitty gritty.
Composing a DIY BI and analytics stack with Flox
To create our combined metabase-postgres environment, we’ll take advantage of Flox’s composability feature. This gives us a way to combine and orchestrate discrete Flox environments into multi-environment runtimes—in this case, by composing pre-built Flox example environments for PostgreSQL and Metabase.
Note: To compose environments, we’ll need to use Flox version 1.4 or later.
Let’s create a new Flox project environment and get started:
$ mkdir metabase-postgres
$ cd metabase-postgres
$ flox initNow let’s run flox edit so we can define the Flox environments we’ll compose as part of a runtime.
# Flox manifest version managed by Flox CLI
version = 1
[install]
[vars]
PGHOSTADDR = "127.0.0.1"
PGPORT = "15432"
PGUSER = "pguser"
PGPASS = "pgpass"
PGDATABASE = "iowa_liquor_sales"
[include]
environments = [
{ remote = "flox/postgres" },
{ remote = "flox/metabase" }
]
[services]
postgres.command = "postgres -D $PGDATA -c unix_socket_directories=$PGHOST -c listen_addresses=$PGHOSTADDR -p $PGPORT"
metabase.command = "metabase"
[options]
systems = [
"aarch64-darwin",
"aarch64-linux",
"x86_64-darwin",
"x86_64-linux",
]The Flox manifest above is the composing environment: this is where we define the included environments. We define included environments in the new [include] section of the manifest, as above. If we want to use included environments as is, we essentially just need this section:
[include]
environments = [
{ remote = "flox/postgres" },
{ remote = "flox/metabase" }
]This gives us pre-configured local PostgreSQL and Metabase instances based on Flox’s example environments. Anything we define explicitly in the manifest of the composing Flox environment overrides equivalent logic defined in the manifests of the included Flox environments.
For this use case, we need to customize some of the environment variables in our vars section, so we do that in the composing environment’s manifest. If we needed to, we could hard-code custom environment [vars], hook and profile logic, and services definitions specifically for this composed environment. As it is, both examples will work with little modification.
Activating the composed Flox environment
Let’s save our changes in flox edit and then run flox activate -s to fire up the composing environment. Once the PostgreSQL bootstrapping completes, we can run flox list -c to view the merged manifest for this environment. I’ll tease just a few lines of the merged manifest below:
[install]
gum.pkg-path = "gum"
metabase.pkg-path = "metabase"
postgresql.pkg-path = "postgresql_16"
[vars]
MB_ANON_TRACKING_ENABLED = "true"
MB_CHECK_FOR_UPDATES = "true"
PGDATABASE = "iowa_liquor_sales"
PGHOSTADDR = "127.0.0.1"
PGPASS = "pgpass"
PGPORT = "15432"
PGUSER = "pguser"
[hook]
on-activate = '''
export PGDIR="$FLOX_ENV_CACHE/postgres"
export PGDATA=$PGDIR/data
export PGHOST=$PGDIR/run
export PGCONFIGFILE="$PGDIR/postgresql.conf"
export LOG_PATH=$PGHOST/LOG
export SESSION_SECRET="$USER-session-secret"
export DATABASE_URL="postgresql:///$PGDATABASE?host=$PGHOST&port=$PGPORT"The composed environment merges and smoothly sublates both its own logic and logic from the included environments. The original [include] definitions are not displayed in the merged manifest.
That’s it. Our composed Flox environment is ready to use. In fact, you can even pull it from my FloxHub:
flox pull –copy barstoolbluz/metabase-postgresThis is how simple it is to create a composed Flox environment for running PostgreSQL and Metabase.
Creating a real-world composed environment for BI and analytics
Let’s look at a more advanced example involving a PostgreSQL database with real-world retail data.
For this example workflow, we’ll use a public data set curated by the state of Iowa’s Department of Revenue, Alcoholic Beverages division. But to avoid sticking Iowa taxpayers with the tab for unexpected data egress charges, we’ve made this dataset available via Google Drive. You can get the environment used in this workflow by running:
git clone https://github.com/barstoolbluz/metabase-postgresThis creates a local copy of a GitHub repo containing both a Flox environment and the scripts you’ll need to:
- Create your
iowa_liquor_salesdatabase; - Download the
iowa-liquor-sales.csvdataset (~7GB); - Import the dataset into PostgreSQL.
You can get the iowa-liquor-sales.csv dataset from Google Drive by running the included fetch.sh script. This environment includes a built-in bash package, so running bash -c fetch.sh will work across any shell. I've also defined logic for Bash, zsh, and fish that aliases (Bash) or wraps (zsh, fish) this script. Running it is as simple as typing fetch and pressing Enter.
Populating the PostgreSQL database
Now that you’ve got the dataset, you’re ready to import it into PostgreSQL. The postgres-metabase GitHub repo provides a pre-configured but empty PostgreSQL database named iowa_liquor_sales. We’ll use the populate-database.sh script to define our data mart's table and columns, and populate them using PostgreSQL’s COPY command. I've created alias and wrapper logic for this, too: just type populate, hit Enter, and your database should start loading.
Note: If you download the CSV directly from the State of Iowa’s website instead of using the provided Google Drive link, be aware that line 21,572,929 contains an error that causes the load to fail.
You can fix it with the following command::
sed -i '21572929s/x904631/904631/' iowa_liquor_sales.csvLoading could take a bit of time. On a 32-core / 64-thread desktop, it runs in under 40 seconds. On a new-ish laptop, it takes just under four minutes. However long it takes, once it’s finished, you’re ready to fire up Metabase.
Configuring Metabase
If you’ve been working with BI and analytics for more than just a minute, Metabase makes the stuff we were using just 10 years ago seem … barbaric. Not quaint: barbaric. Let’s briefly walk through how to set up Metabase so we can use it to query against our local PostgreSQL data warehouse.
This is trivially easy. First, open up a web browser and paste in the following URL:
http://localhost:3000If localhost doesn’t work, you can try 127.0.0.1 or even your hostname. (Some Linux platforms, like Linux Mint, default to 127.0.1.1, for reasons unknown to me.) That should open up the Metabase welcome screen:
Clicking the “Let’s Get Started” button takes you to an intuitive user-creation wizard.
Next is the “Add your data” wizard. Metabase actually supports dozens of data sources, which you can expose by clicking the “Show more options” button. Because we’re using PostgreSQL, we’ll go ahead and click on Slonik, the PostgreSQL elephant mascot.
This opens up an intuitive database configuration wizard.
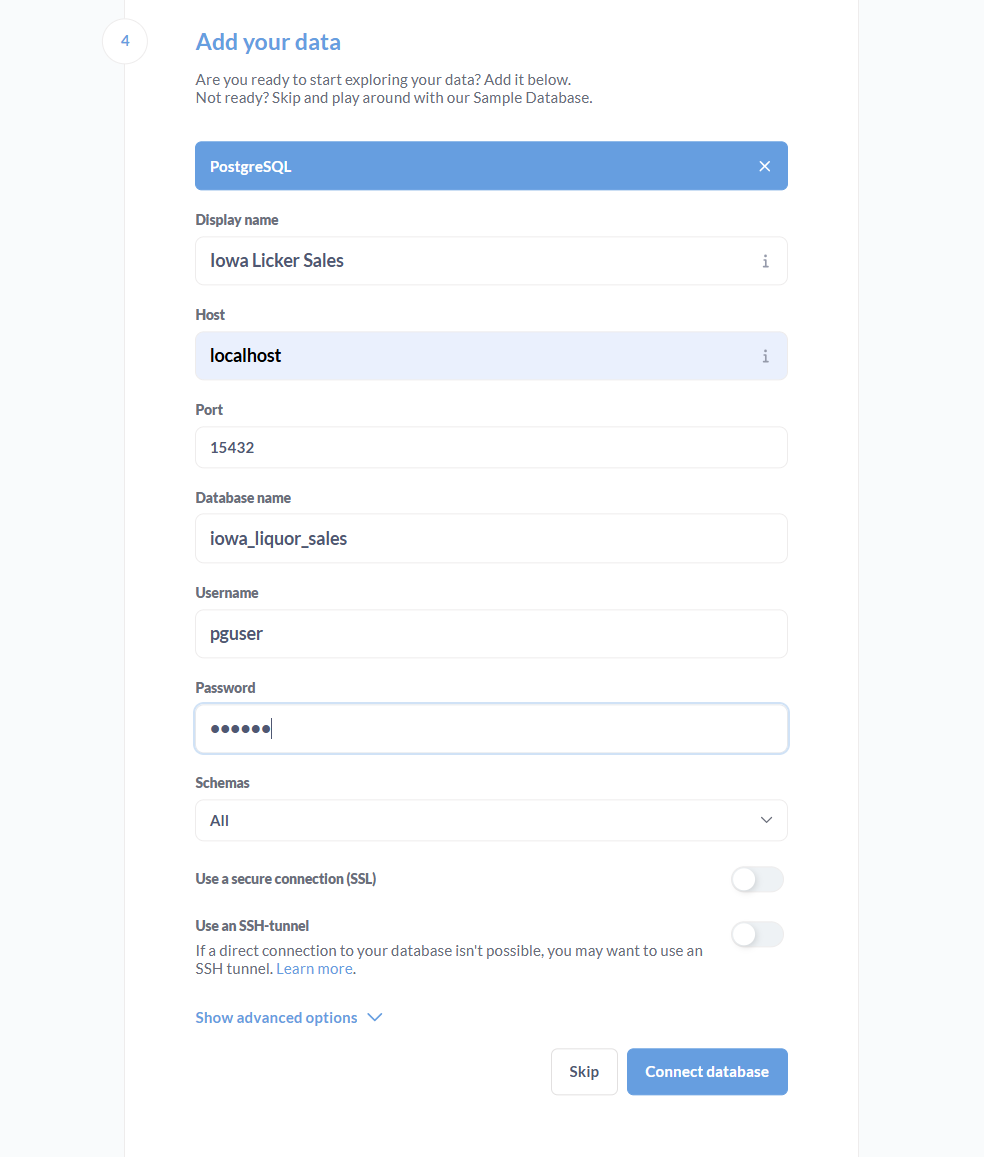
The defaults for connecting to this database are as follows; just configure them and click “Connect database.”
Display Name = <anything_you_want>
Hostname = Localhost
Port = 15432
Database name = iowa_liquor_sales
Username = pguser
Password = pgpass
Schemas = AllThat’s it. Metabase should be configured to work with your PostgreSQL retail data warehouse!
Now let’s put it to use.
Using Metabase
On first run, Metabase offers a battery of basic analytics you can run against your data. The data model we’re using is pretty basic (see Building the Perfect DBeast, below), so there’s not much to show here:
“A look at Iowa Liquor Sales,” provides a general overview (with up to three selectable fields) of the data set.
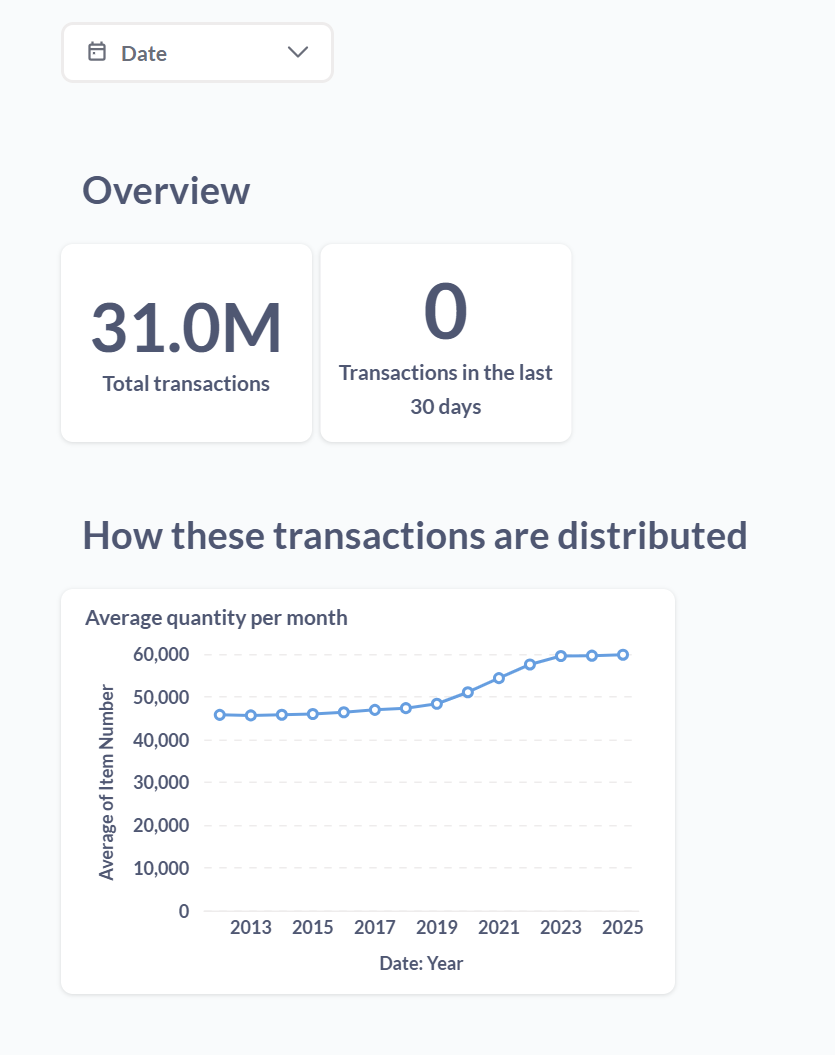
Let’s try running an ad hoc query. This is as simple as clicking the blue “+New” box in the top-right corner of the Metabase UI and selecting “>_SQLquery” from the drop-down menu.
This opens up a window where you can author (or paste) SQL logic. We’ll query as to how many top-shelf bottles of Scotch, bourbon, tequila, cognac, and vodka were sold in the state of Iowa between 2012-2025.
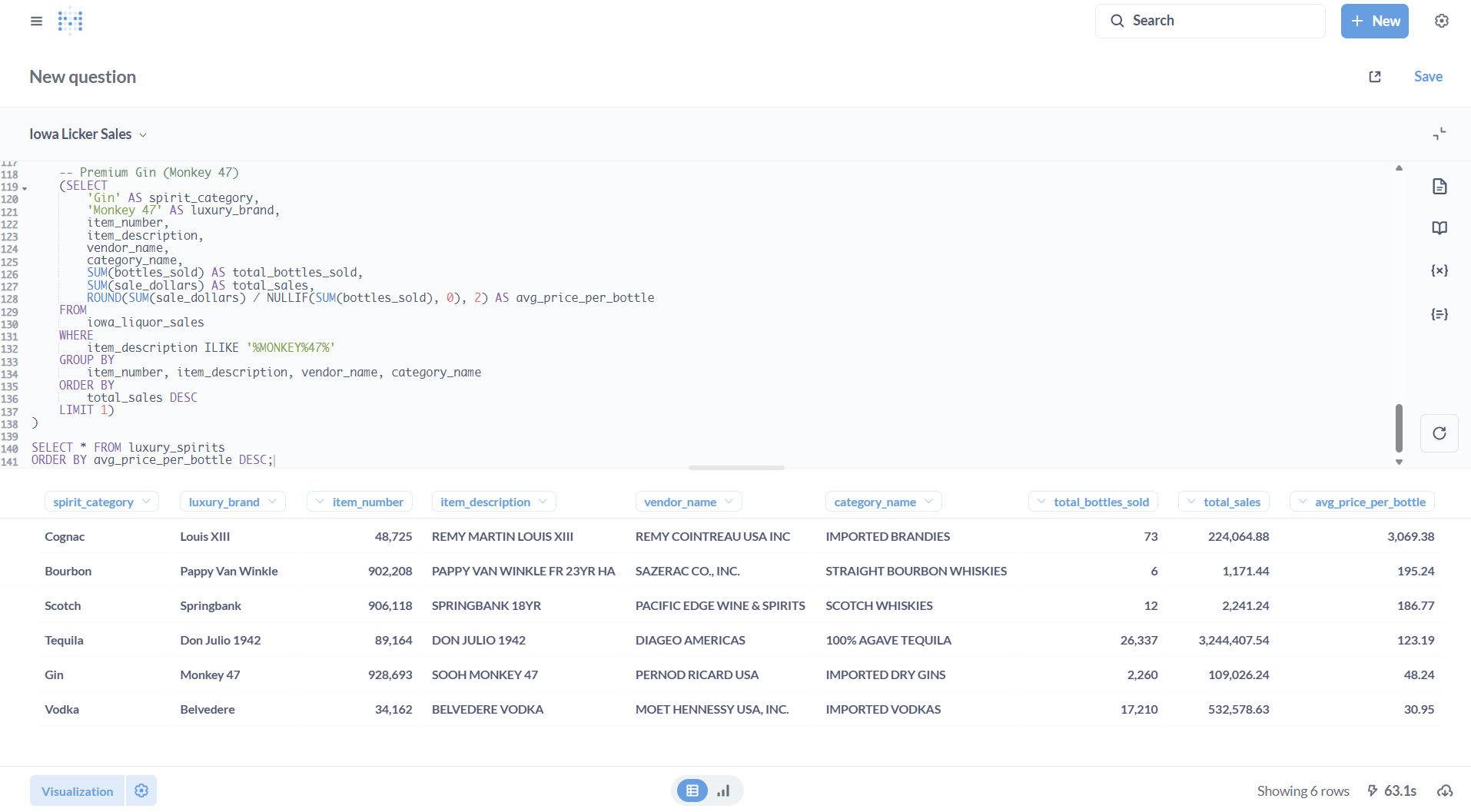
Blah: a table view. It’s useful and informative, but tells us little at first glance. Let’s visualize it:
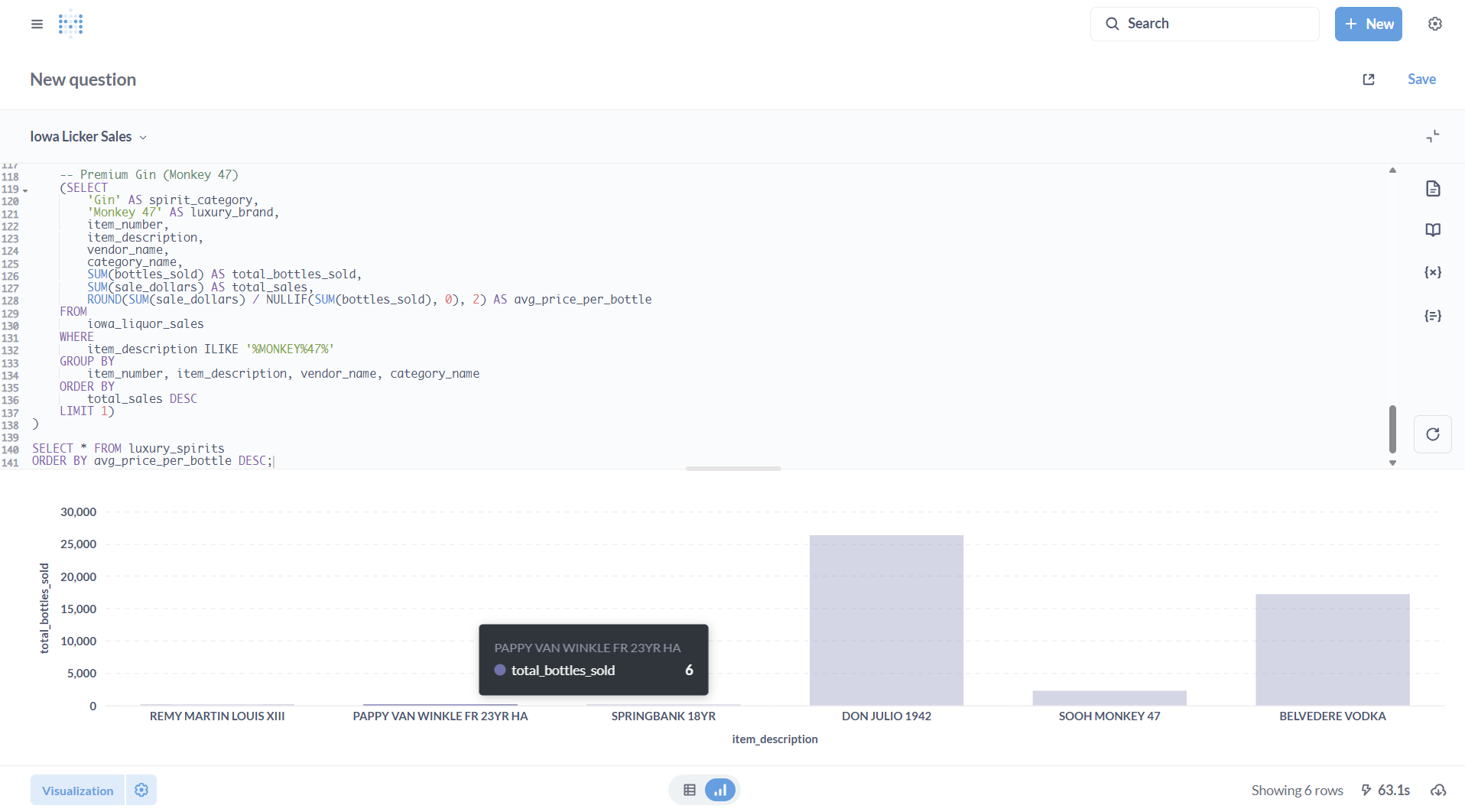
Six bottles of Pappy Van Winkle bourbon sold over a 12 year period!
One last ad hoc query: How about college standbys like Jägermeister and Goldschlager? Are they still popular? If we enriched our dataset with census data and enabled PostgreSQL GIS extension, we could do some neat things in terms of correlating sales of both with college campuses. This is a heavy lift, however, for a guide like this, so let’s instead look at preferences across counties.
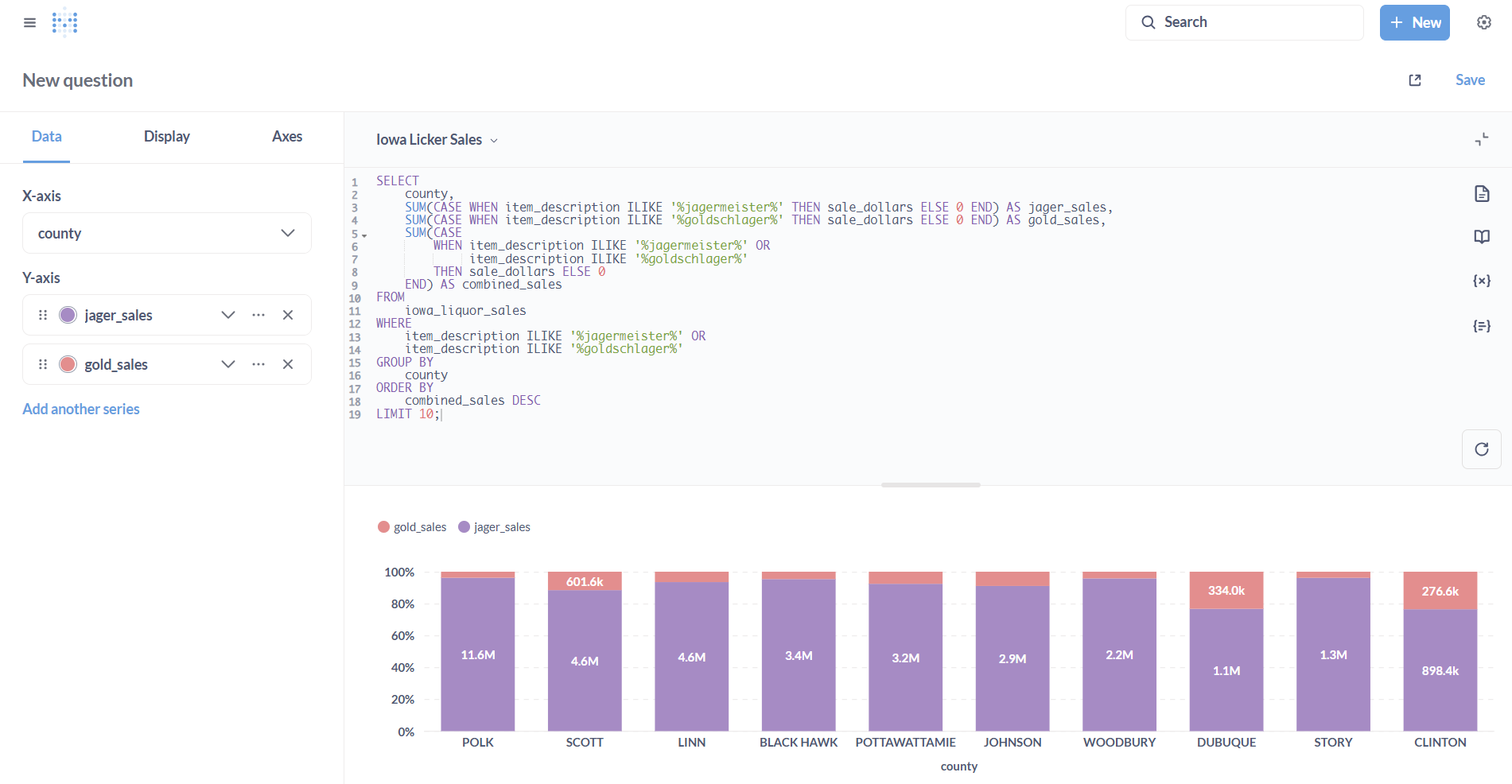
The verdict: Basically every Iowa county strongly prefers Jägermeister to Goldschlager! Who knew?
Before we wrap up the usage walk-through, let’s briefly explore Metabase’s dashboarding capabilities.
Let’s say you’re obsessed with sales of Pappy Van Winkle and want to know as soon as that seventh bottle gets sold. You have a saved SQL query you run a few times a day … so why not put it in your dashboard?
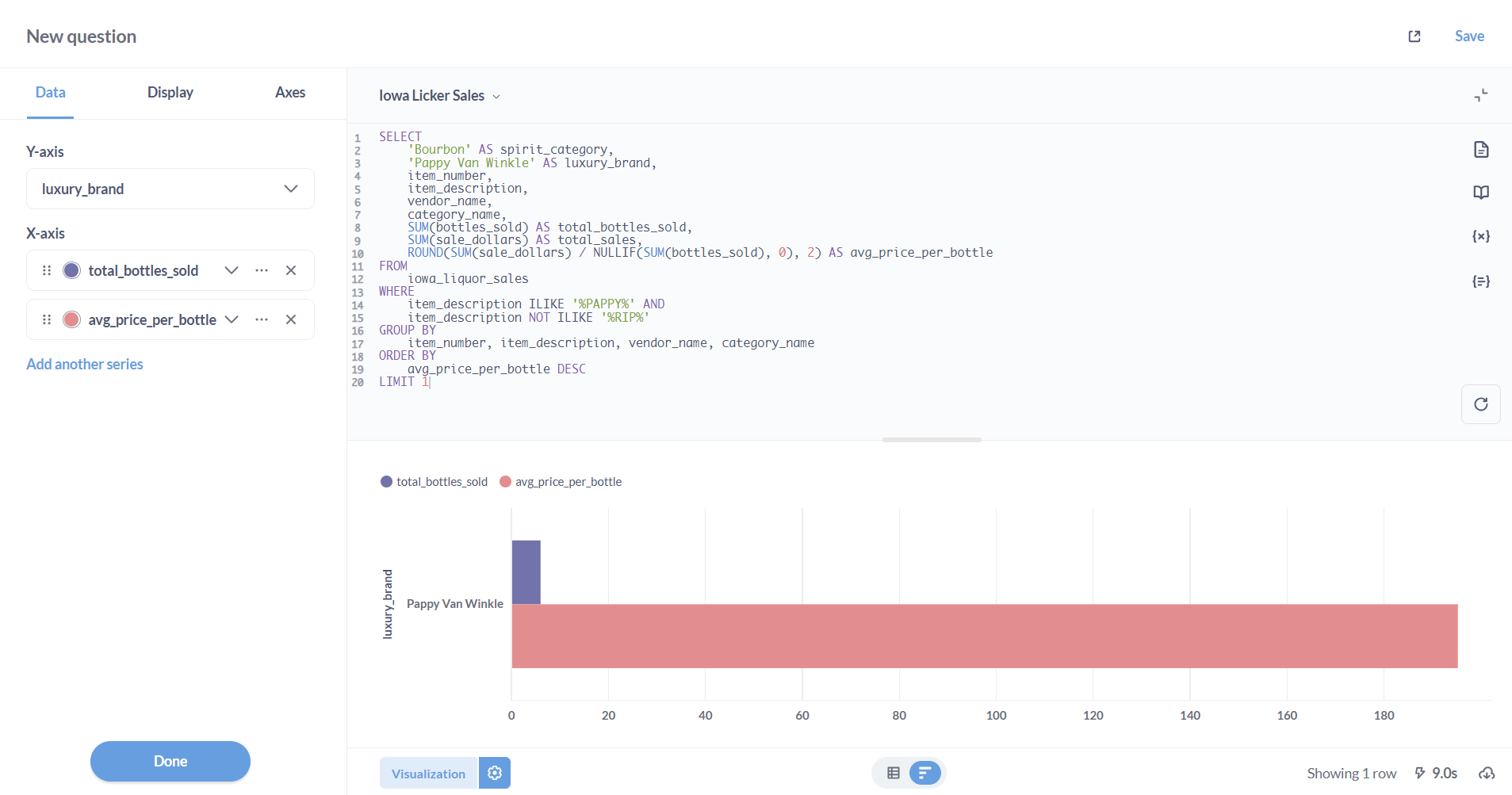
You can start by clicking “Save” in the top right-corner of the Metabase UI, complete the “Save new question” wizard, and then click “Yes please!” in response to the “Saved! Add this to a dashboard?” prompt.
Select the dashboard you’d like to add it to, and then you’re given a chance to see it in context:
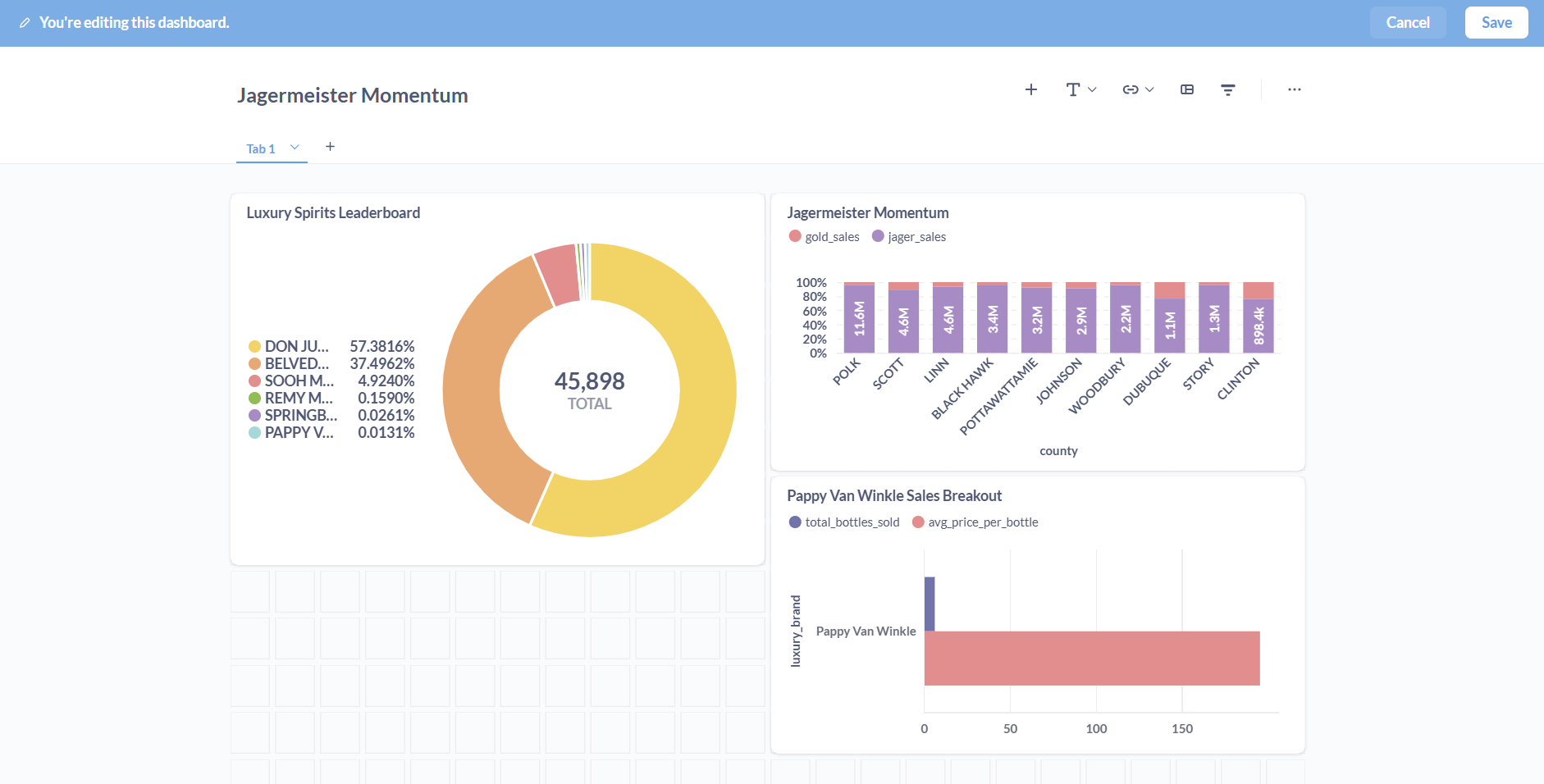
Building the perfect DBeast
The included populate-database.sh script creates a database table that mirrors the structure and contents of the CSV file, without optimizing for query performance. Rather, it’s designed for rapid database loading. With a basic data model of this kind, ad hoc SQL queries—and complex Metabase models especially—can take a long time to run.
So I put together a more production-worthy version: a multi-stage Python ETL pipeline that builds a proper star schema—complete with dimension and fact tables, type conversions, geospatial conversion via PostGIS, chunked processing, parallel execution, checkpointing, error handling … you get the idea.
This is way too heavy-duty for a guide like this! But I’m including it because it demonstrates why dev-time reproducibility is essential. Creating this pipeline took me a few days of running, debugging, and fixing Python code, testing and retesting against a local PostgreSQL instance.
It’s the kind of iterative work that grinds to a halt when you add a dependency that breaks your environment in some weird, hard-to-debug way. Unless you’re working in a reproducible dev environment—where packages can’t conflict because they’re built and stored in isolated paths, allowing multiple versions of the same dependencies to coexist.
Iterating on schema and ETL, not your dev environment
Say I have a Flox environment that I use solely for Python-related DBMS work. I invoke this environment whenever and wherever I want by taking advantage of two of Flox’s killer features: one, remote activation; two, layering
$ flox activate -r barstoolbluz/python-postgresIn this pattern, I remotely activate my python-postgres Flox environment and layer it on top of my postgres-metabase environment. This way I’m able to work on my local system, with transparent access to local tools, data, secrets, aliases, and so on. Even better, I don’t have to configure container networking or bind mounts between the container runtime and the host. And I don’t have to penetrate a container or ssh into a VM to install missing dependencies, add or change environment variables, inject secrets, etc. I get all the basic Python tools and requirements I need when I’m working with databases like PostgreSQL, including:
pip.pkg-path = "python312Packages.pip"
gum.pkg-path = "gum"
zlib.pkg-path = "zlib" # required for building, compiling, and using psycopg2
gcc-unwrapped.pkg-path = "gcc-unwrapped" # required for building and compiling psycopg2
sqlalchemy.pkg-path = "python312Packages.sqlalchemy"
alembic.pkg-path = "python312Packages.alembic"If I need a different version of Python, I can just edit the Flox python-postgres environment’s manifest. If I need to add Python or global dependencies, I can install them imperatively (using flox install) without blowing up my environment … or my system.
Wrapping up
My workflow involves the following steps:
- Running
schema-creation.pyto instantiate a star schema data model in myiowa_liquor_salesdatabase; - Debugging
schema-creation.pyto fix DDL issues and Python-specific errors in logic; - Running
import.pyto extract and transform data from the CSV, loading it intoiowa_liquor_sales; - Debugging errors in import.py across ~100 runs as data / logic / assumptions change;
- Running unit tests to validate that the database is correctly populated and queryable.
Both import.py and its associated schema-creation.py script are located in the ./resources folder in the GitHub repo. The import.py script still isn’t quite where I’d like it to be, but it works—queries are (on average) 300%-400% faster!
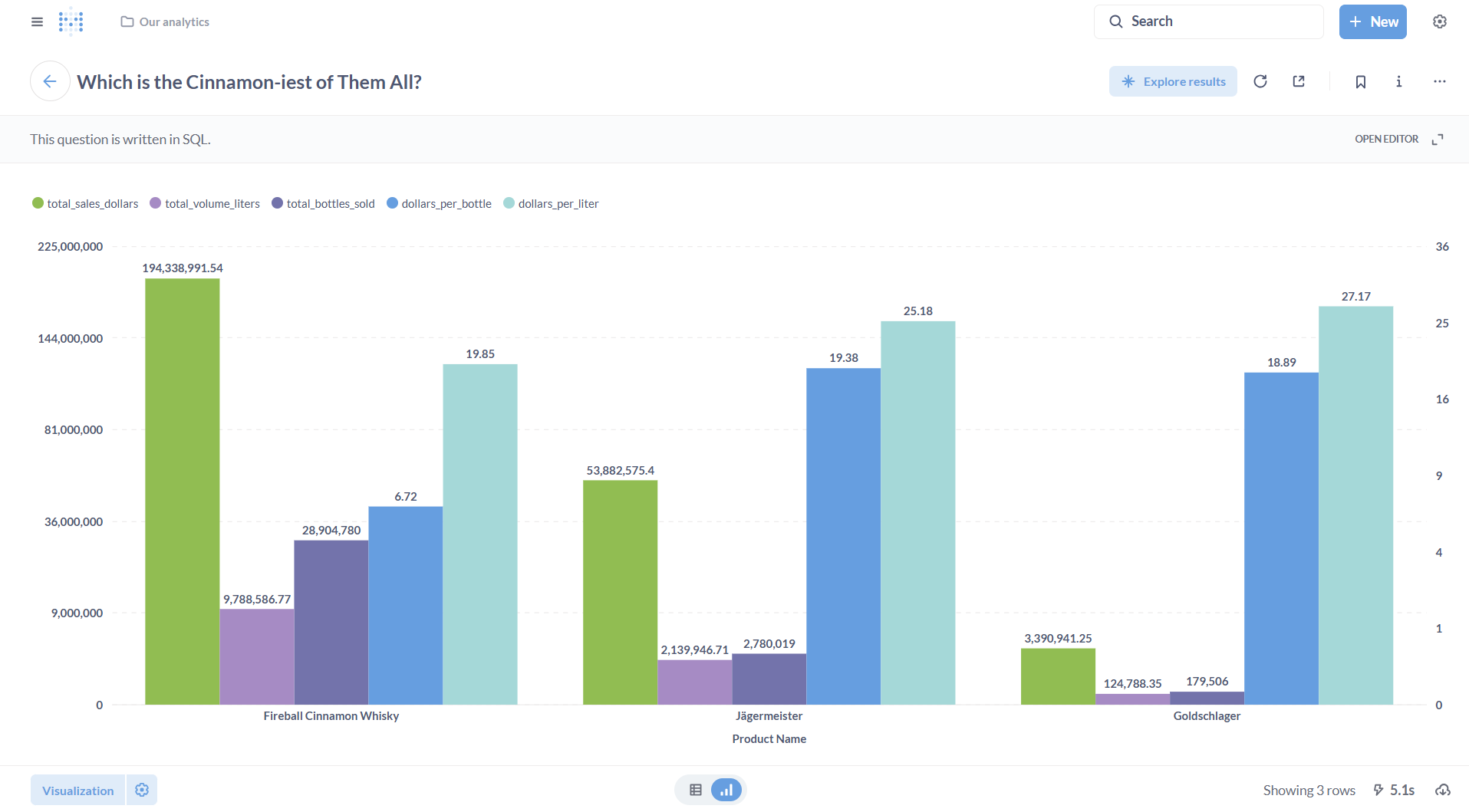
The following screenshots show the same query—used to compare sales performance for Jägermeister, Goldschlager, and Fireball Cinnamon Whisky across five dimensions: total sales (USD), volume (liters), bottles sold, price per bottle, and dollars per liter.
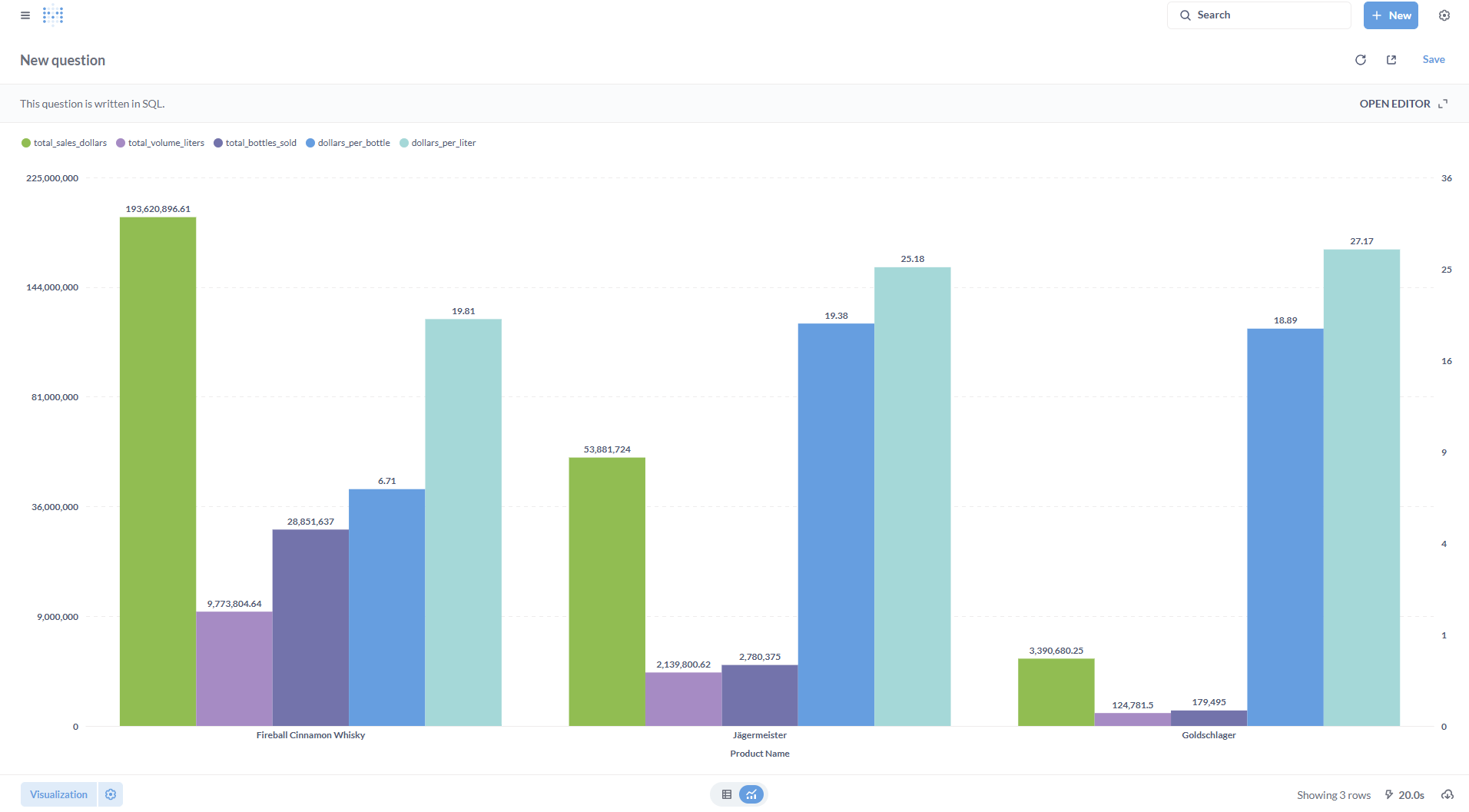
The first shows the non-optimized data model (query runtime: 20s); the second, below, shows the optimized version (runtime: 5.1s).
One final note: once it’s time to ship this environment, Flox gives you several options. You can:
- Bake it into a container. Running
flox containerizebakes the environment into a container image so you can push it to a registry; - Push it to GitHub. This gives you your code and runtime dependencies in one place.
- Push it to FloxHub. The easiest way to share. Users just
flox pulland run locally.
No matter how you ship—even to serverless platforms like AWS Lambda—Flox fits into your workflow.
Build wherever you work. Run wherever you need
Flox makes it simple to build and ship a runtime environment for data work. You can build locally, on your own system, in your $HOME shell, with direct access to local tools, data, env vars, secrets, and other resources. You can add or remove dependencies as needed, up to and including activating required tools or frameworks on-demand—all without changing your system-wide configuration, or modifying anything in your $HOME.
Flox permits a declarative approach to defining—and changing—runtime software. For example, This guide uses Postgres, but Flox also offers a pre-built example environment for MariaDB (MySQL). Just run flox pull --copy flox/mysql to start building your own MariaDB/Metabase BI and analytics environment.
Don’t want to use PostgreSQL or MariaDB? How about building locally for Aurora in AWS? Flox has a LocalStack environment you can use for that as well. Just run flox pull –copy flox/localstack and start customizing.
Intrigued? Flox is free to download and uses a syntax similar to git and npm, so it's easy to pick up and master. Why not check it out?