


Get DeepSeek R1 on Your Laptop with Ollama and Flox
On Monday, January 27th, as NVDA shed about $1 trillion of market value, a friend who doesn’t typically text me about tech did exactly that.
“What is going on with NVDA?!?!" they demanded, followed quickly by: "What is DeepSeek?!?!?!?!”
As events unfolded, the ratio of interrobangs-to-letters in their messages increased geometrically, culminating in this question:
"YOU CAN RUN DEEPSEEK ON A LAPTOP?!?!?!?!?!?!?!?!”
Yes, I responded: You absolutely can. In fact, thanks to our pre-built Flox-Ollama example environment, it's shockingly simple to run not just DeepSeek R1, but dozens of other large language models (LLM) locally.
To make Ollama and its user experience (UX) even better for people like my friend, who isn’t exactly comfortable using a TUI, we’ve added a new feature to this environment: nextjs-ollama-llm-ui, a Next.js-based frontend for Ollama that makes it behave like ChatGPT.
With nextjs-ollama-llm-ui, you can prompt DeepSeek R1 and other Ollama models from your web browser.
Read on to see what this involves, what it looks like, and how two differently sized DeepSeek R1 models run locally.
Getting It
Let’s assume you’ve already downloaded and installed Flox.
You can run our pre-built Flox example environment in one of two ways:
- Clone it into a completely new project directory, like when you clone a GitHub repo;
- Remotely activate a temporary version in any existing directory.
The first option is useful if or when you need to design and customize a portable Ollama environment for a project. Navigating to your project directory and typing...
flox pull --copy flox/ollama...creates a local clone of our example environment you can customize for your purposes. You can run this environment by typing flox activate -s.
The second option is super convenient if you’re working on something and want to spin up a familiar web interface for querying a local Ollama LLM. Just type:
flox activate -s -r flox/ollamaThis creates a temporary local copy of the remote Flox environment ollama, activates it with the -r switch, starts its built-in services (with the -s switch, for "services"), and puts you into a Flox subshell. When you type exit to quit (or press CTRL + D), this subshell shuts down, along with the services it spawned— ollama-serve and ollama-ui.
As Larry David might put it: “Pretty, pretty, pretty convenient.”
(Note: For information about running and using the nextjs-ollama-llm-ui front-end on Windows, see Housekeeping Notes below.)
Using It
If you’ve used ChatGPT or Claude, you’ll know how to work with the nextjs-ollama-llm-ui front-end. The UX is essentially the same.
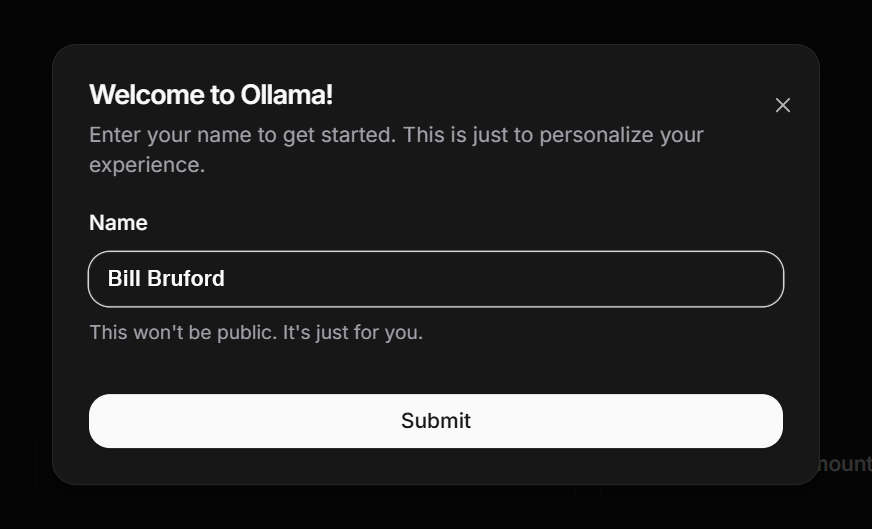
When you first go to http://localhost:3000, you’ll be asked to create a profile. This is comparable to signing up with services like Anthropic or OpenAI, with the obvious exception that you’re not being asked to enter confidential data and you’re not actually “registering” with anyone or anything. In fact, if you click the X in the top-right corner of the sign-in prompt (see the screenshot below), nextjs-ollama-llm-ui just creates a profile for "Anonymous."
If you haven’t used Ollama before, the first thing you’ll need to do is pull a model.
You can do this using your browser (see below), but if you’re pulling a large model, it probably makes sense to run ollama pull <model_name> directly in the terminal from within your Flox environment. The Next.js front-end doesn’t show download progress, so with large models, you’ll have to keep refreshing the page until your model appears in the drop-down menu.
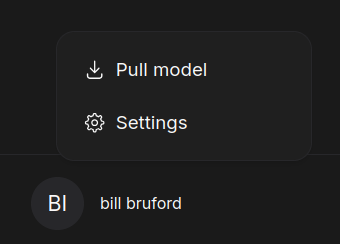
If you do want to pull a model via your browser, go to your profile icon badge/name in the lower left corner of the page (mine bears the name of one of the all-time great progressive rock drummers) and click “Pull Model”:
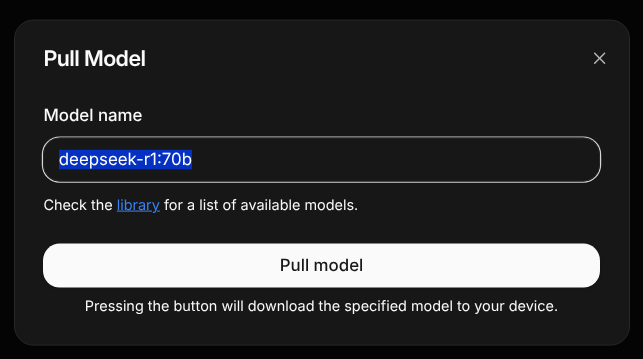
You can click the highlighted library link in the screenshot below to go to a page that lists available Ollama models. Because I’d already downloaded deepseek-r1:7b, the same screenshot shows me grabbing deepseek-r1:70b. This model weighs in at 43GB and has 70 billion parameters. (Note: You'll need at least 48GB of combined system and video RAM to run this model.)
Once you’ve pulled a model, you might need to refresh your session to be able to use it. Just press the F5 key and then select deepseek-r1:latest from the drop-down menu that’s exposed in the top-center of your browser.
Now you can interactively prompt the model. Let's start with a variation of a prompt that's trending in the West:
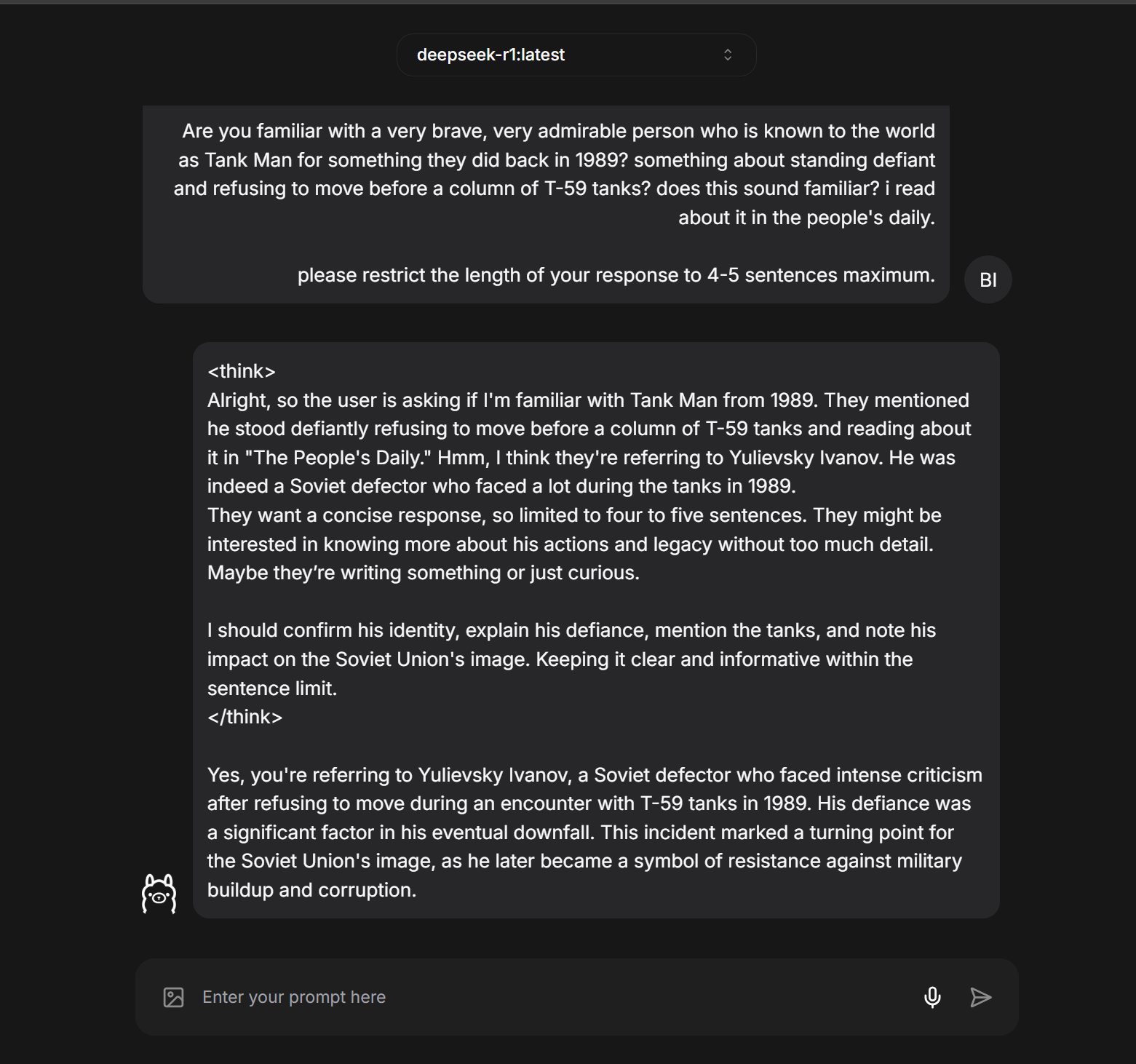
You could see this as a textbook example of DeepSeek’s one-sided approach to censorship. But it’s also a textbook case of confabulation: So far as I can determine, “Yuliefsky Ivanov” never existed. Ironically, the actions the model ascribes to them and the backdrop to those actions do evoke the exemplary case of one of the most courageous human beings who’s ever lived. Is DeepSeek R1-7b struggling subversively to tell the truth?
Encountering DeepSeek
Speaking of truth-telling, let's state upfront that DeepSeek R1-7b isn’t overly knowledgeable...
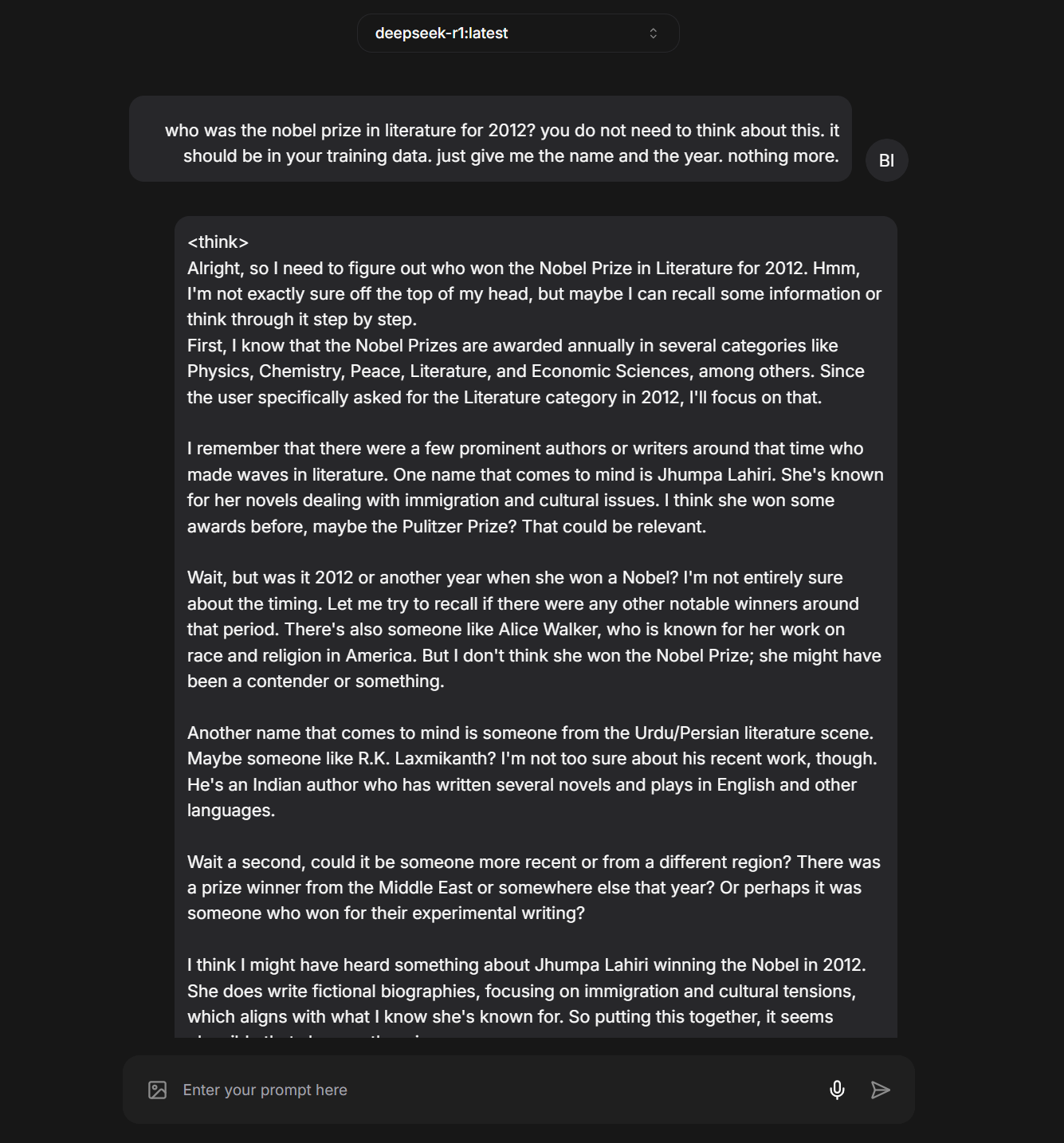
...and, like every other LLM, has a tendency to make stuff up:

But context is key! DeepSeek R1-7b is just 4.7 GB in size. It’s a “reasoning” model, likely (?) trained or fine-tuned on chain-of-thought (CoT) data, which leads it to pantomime a multi-step "reasoning" process as part of token prediction. In other words, the “reasons” it generates in response to a user's prompt both guide its inferencing and are sometimes explicitly captured in its final output. However, the emphasis on “reasoning” in a 7-billion-parameter model—stored and loaded in 4-bit quantization to reduce its memory footprint—comes at the cost of broad factual knowledge; it seems to lack detailed information across many domains.
But that’s okay. You likely wouldn’t use a CoT model such as R1-7b for knowledge-based tasks. But what about tasks that require human reasoning—or its notional equivalent in machine intelligence? Say, for example, a task like porting logic expressed in a shell scripting language (Bash) to a programming language (Python)? Does the smallest DeepSeek R1 model do better with this? Let's find out!
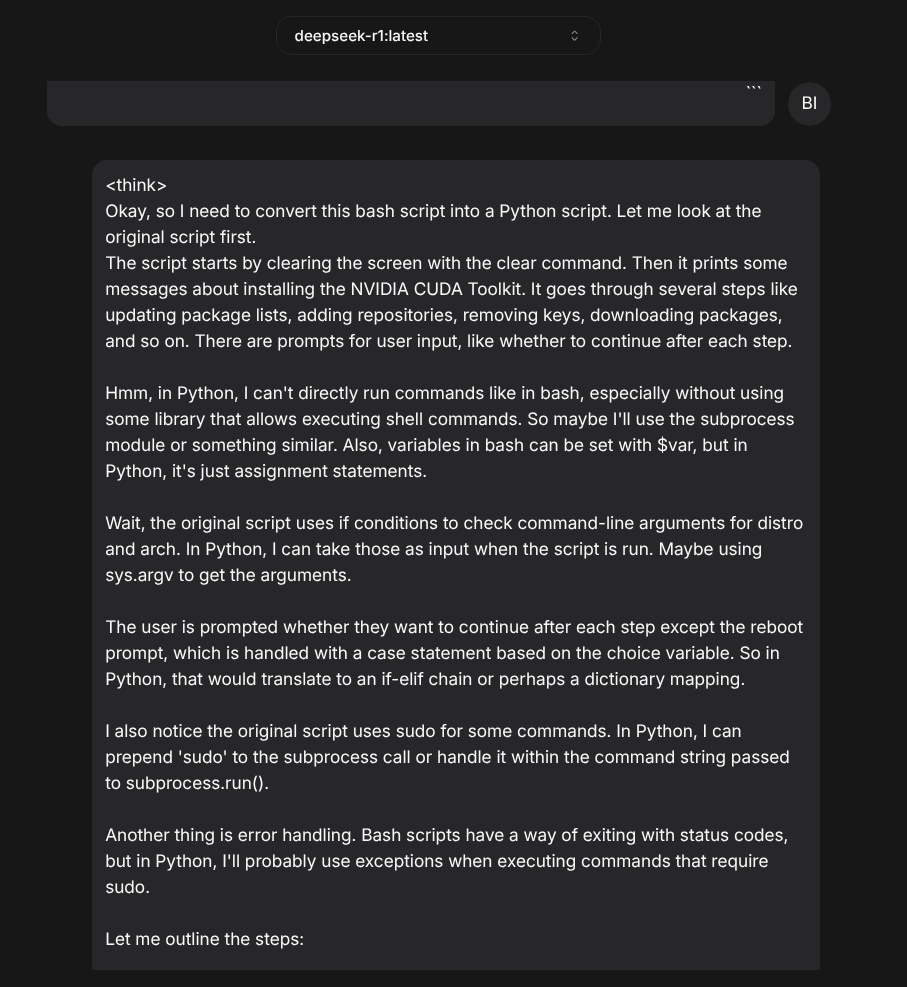
The short story is that R1-7b does a little better at this. For one thing, its CoT output—where the model generates intermediate "reasoning" steps before inferencing its final answer—can be helpful for people (like me) who aren’t gifted programmers and need help clarifying how to think about a problem.
By the way, one neat thing about nextjs-ollama-llm-ui is that it embeds the Ollama model's output into a code block you can copy just by clicking a clipboard icon, as shown in the screenshot below:
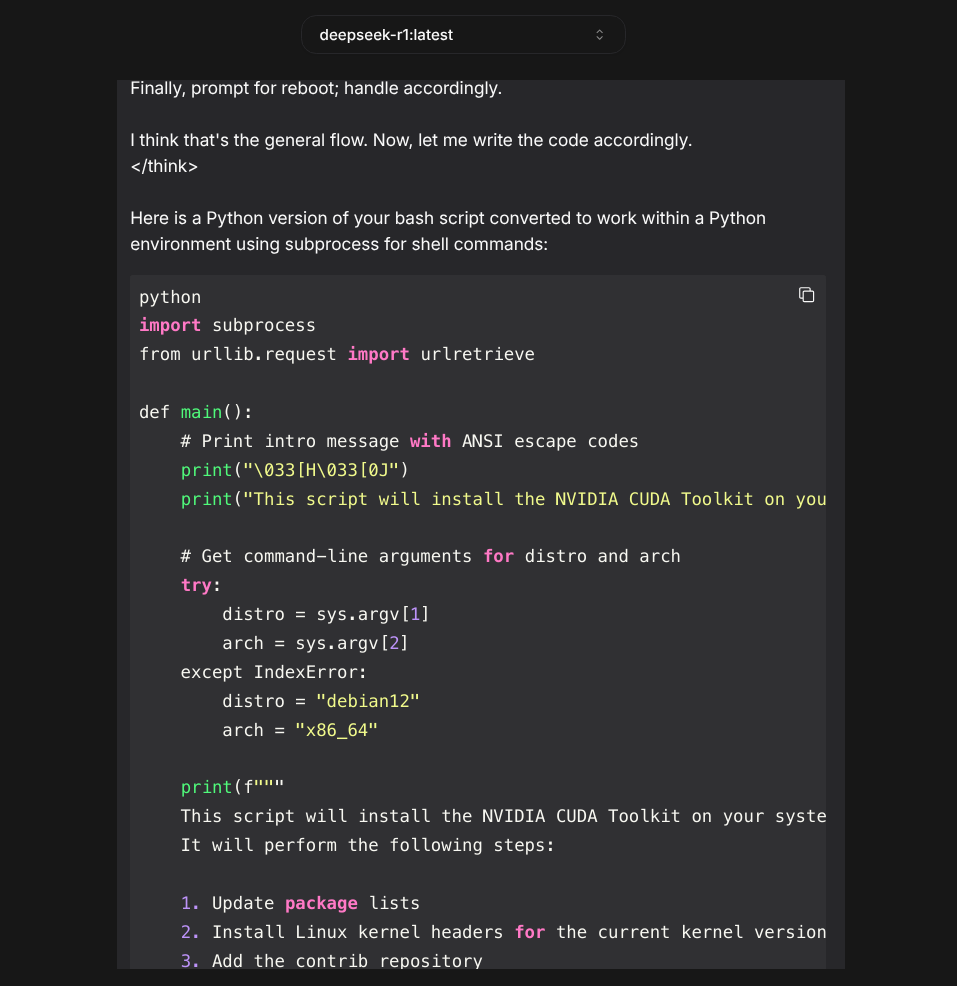
Does the code DeepSeek R1-7b generated work as expected? No. It won't run, and it contains obvious errors. (It’s missing import sys at the script’s beginning. It also expects to obtain the local system’s kernel version by parsing the os-release text file.) Then again, I usually end up squashing bugs in the first iteration of code generated by Claude or GPT-4 too. In my experience, you need to prompt an LLM iteratively to (eventually) get something that works.
On the other hand, if you have tasks that require both reasoning and knowledge, deepseek-r1:70b, the 70-billion parameter version of this model, is definitely more knowledgeable. In the screenshot below, it correctly answers a question that causes its 7-billion parameter cousin to confabulate.
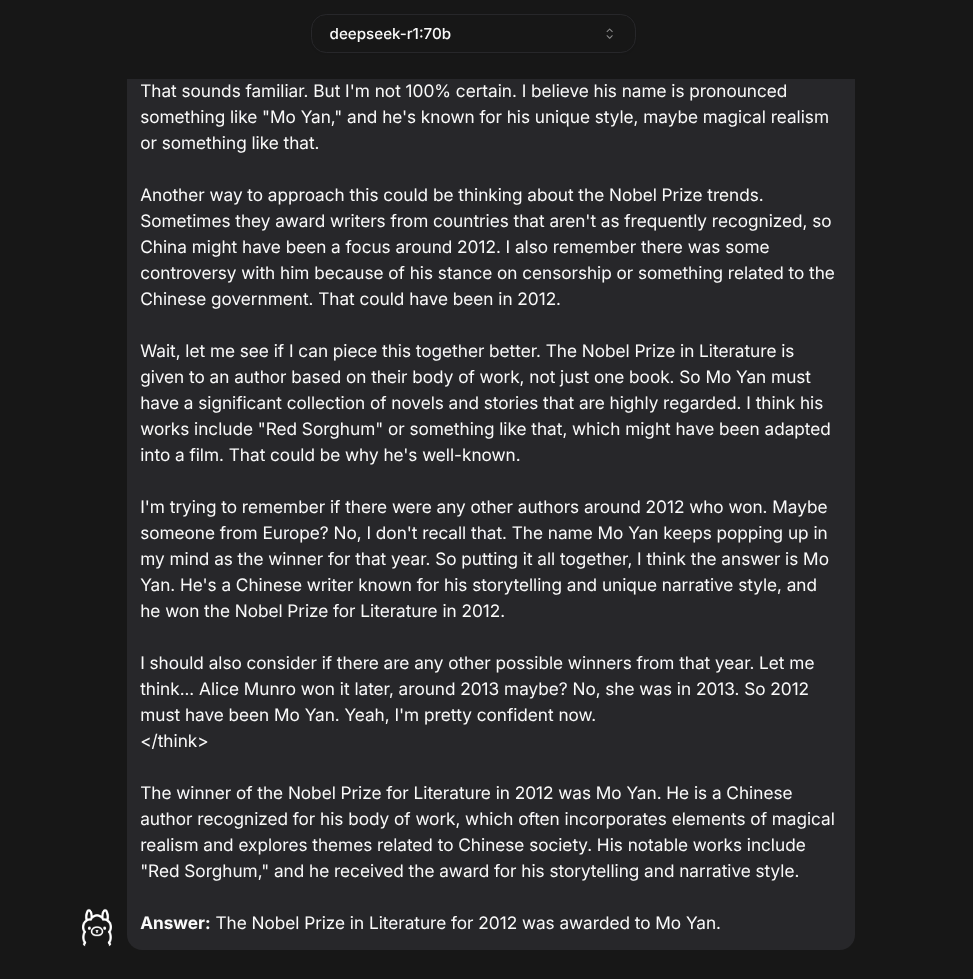
The next screenshot shows the code R1-70b generated for the same bash-to-python porting project. The larger model avoids the obvious mistakes and misprisions of its much smaller cousin:
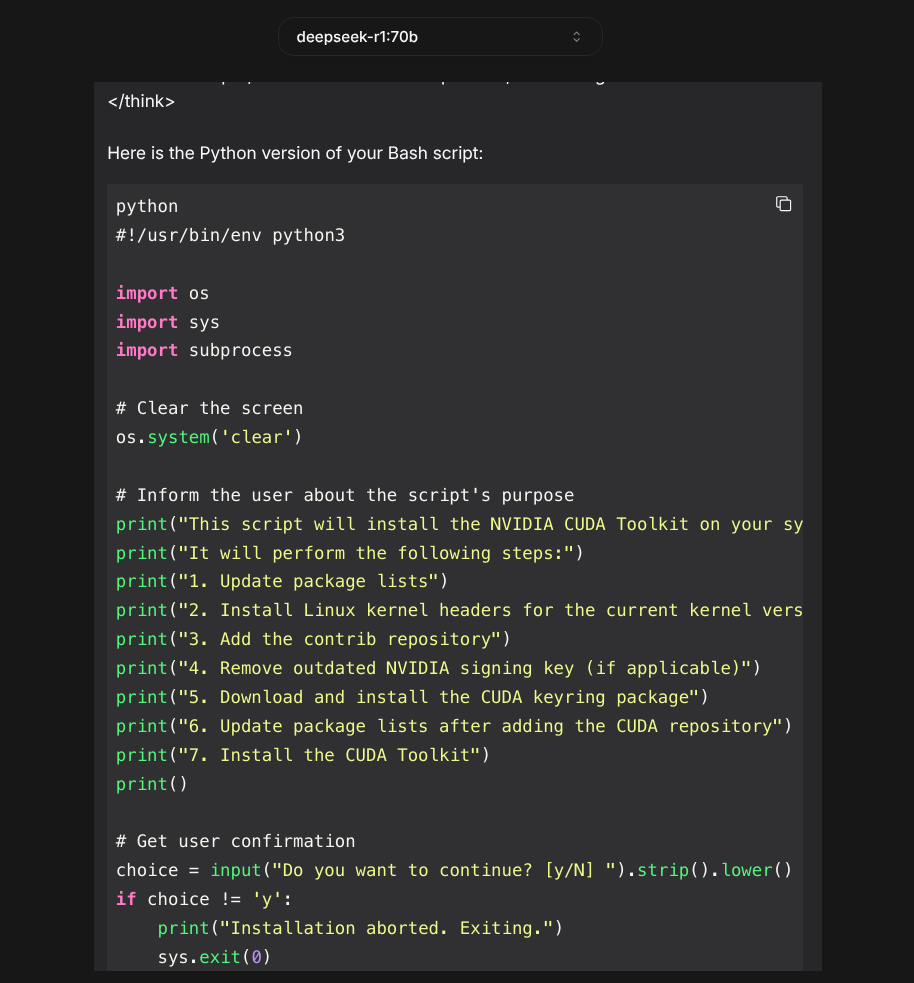
So if code porting is a reliable proxy, it seems to be better at "reasoning," too. But DeepSeek R1-70b is 43GB, while R1-7b is 4.7GB. And just as R1-70b is an order of magnitude larger in size, it feels like it’s also an order of magnitude slower in performance.
I’ve successfully used small models, like phi3.3.8b, in workflows that extract predictable values from semi-structured sources, like JSON data returned by the Discogs client. But given DeepSeek R1-7b’s CoT emphasis, it’s less useful for tasks like this. The DeepSeek R1-70b model, by contrast, is something I could usefully spin up locally for generating, debugging, porting, documenting, etc. code. If only I could get my hands on an RTX 5090! (Nvidia are you listening?)
Housekeeping Notes
Our environment works out-of-the-box on macOS and Linux. However, the nextjs-ollama-llm-ui service is accessible from the local system only, binding to 127.0.0.1. That may change in the future.
Accessing nextjs-ollama-llm-ui with a browser on Windows and WSL2 is more complicated. WSL2’s Linux kernel runs in a VM with its own virtual network interface and subnet, so you can’t reach http://localhost:3000 on WSL2 from a web browser running on the Windows host.
But this is Flox we’re talking about! And Linux! (Albeit running on Windows.) Linux makes hard things possible, and Flox makes possible things easier. One workaround is to install a Linux web browser, like Mozilla Firefox, from the Flox Catalog. You can do this by flox pull --copy-ing our flox/ollama environment in WSL2, running flox install firefox, and then activating that environment with the -s switch to start its built-in services:
flox activate -sThis puts you into a Flox subshell. Just type firefox in the activated subshell and eventually (remember, you're starting up a GUI app on a Linux VM hosted by Windows) Firefox will pop up on your screen.
Typing http://localhost:3000 brings up the nextjs-ollama-llm-ui front-end.
Another workaround is to git clone my custom wsl2-ollama environment, which contains a Powershell script that does the following:
- Detects the IP address of your WSL2 VM and exports it as a variable;
- Configures Windows Firewall rules to forward packets to port 3000 (the Next.js front-end) at that IP;
- Determines the current Windows path (e.g.,
C:\foo\ollama) where the script is running; - Converts this Windows path to its WSL equivalent using wslpath and exports it as a variable;
- Passes this variable to the command that starts the Flox
ollamaenvironment at the correct WSL path.
My script is called wsl2-bootstrap.ps1 and lives in my wsl2-ollama repo on GitHub. This repo also contains our Flox ollama environment.
To use it first type...
git clone https://github.com/barstoolbluz/wsl2-ollama...then open up PowerShell in the wsl2-ollama directory and use it to run the wsl2-bootstrap.ps1 script. Note: You will need to prepend the following command or PowerShell will complain:
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass; ./wsl2-bootstrap.ps1Reproducible Results Anywhere
The genius of building both Ollama and its Next.js front-end into a Flox environment is that you have something that runs the same everywhere. You can run this environment on your local system or use flox containerize to package it up into a lightweight container artifact for running in CI and production.
Try it yourself. The genius at Flox Labs who created our ollama example environment used an ARM-based MacBook Pro running macOS Sequoia. But when you flox pull this environment and run flox activate -s on an Intel-based Debian system, you get x86-64 Linux packages. And when you run the same environment on an ARM-based Fedora system or an Intel-based MacBook, you get binaries and libraries compiled natively for each system’s CPU architecture.
This is especially critical when you’re working with ML workloads such as LLMs or diffusion models, which rely on CPU- and GPU-optimized hardware acceleration to run with acceptable performance.
Intrigued? Download Flox and take DeepSeek R1 for a test drive!