


Reclaiming the SDLC
Fragmentation is the defining characteristic of software development today.
This might seem counter-intuitive. After all, CI/CD is supposed to boost developer velocity by emphasizing automation and repeatability.
But even though CI/CD gives us standard patterns for building and shipping software, it doesn’t give us shared standards for implementing these patterns. Nor does it standardize how teams work. Instead, it provides a reliable, repeatable way to encapsulate a wide variety of different ways of doing this work.
The upshot is that CI/CD isn’t coextensive with the SDLC, however much we’d like it to be. It’s kind of like a wrapper for the SDLC, imposing just enough structure to permit automation, usually by standardizing and automating tasks where automation yields clear, agreed-upon benefits—like repeatable builds, tests, and deployments—while leaving the majority of the SDLC outside its scope, under local or team-specific control.
But a wrapper can only standardize what’s encapsulated within its boundaries. Outside the scope of CI/CD, differences in repo strategy, pipeline design, artifact management, local development, and even semantics are just a few of the myriad sources of fragmentation that ripple and propagate across testing, CI, and production.
We’ve spent decades trying to solve the problem of fragmentation in software development—with little to show for it. But are we missing something? Has a solution been right in front of us for more than 20 years?
CI/CD uses the same words, but smooths over the different languages
CI/CD imposes a surface sheen of structure that masks fragmentation—beginning with how it’s implemented.
When three team leads in a large org get together to talk about building and shipping software, they can’t assume commensurability between how they do what they do—even if, in comparing their workflows, they recognize familiar structures.
All three team leads might use similar language—e.g., “We test everything together,” “We validate dependencies,” “We roll back deployments as needed”—but in reality they’re talking about different things because they’re each working from different prior assumptions about how to build and ship software.
For example, in reality:
- One team uses a monorepo, another a polyrepo, and another a hybrid approach;
- Two use an imperative CI/CD pipeline, the other a declarative one;
- All three implement infrastructure-as-code patterns, but use different tools and methods.
Once you drill down into these patterns, you find plenty of local variation. Those two teams using imperative CI/CD pipelines? They use the same high-level stages, but their pipeline DAGs diverge: one runs everything in sequence—build, test, security, deploy. The other parallelizes as much as possible, kicking off tests and security scans alongside the build to cut feedback time. Same high-level stages, different pipeline behavior.
Your SDLC: From a one-way stream to a circulatory system
Another source of fragmentation is what I call the “one-way stream” problem.
After teams build, ship, and deploy software, they rarely have a reliable way to track where it runs, who’s using it, and how it’s deployed. This is especially problematic in regulated industries like healthcare and finance, where compliance and traceability are mandated by regulations and statutes. To “manage” this, organizations typically try to create manual tracking processes, which introduce both overhead and the possibility of error.
What’s needed is the SDLC equivalent of a circulatory system, such that every build, dependency, and deployment cycles through a traceable loop. Nothing bypasses the loop: every change is registered, every artifact tracked, and every state reproducible. This circulatory model keeps software observable, auditable, and reproducible across its lifecycle. This invites the question: what would this vision of the SDLC look like?
How about this? At a minimum, orgs must be able to track:
- The source code used in a build (commit, branch, repo state).
- The exact build process that produced the artifact (build script, environment, compiler, flags).
- The full set of dependencies in the final artifact (including transitive dependencies).
- The artifact’s immutable digest, tied to the source, config, and environment that built it.
- The runtime config and deployment context, if they influence artifact’s behavior or provenance.
But most build systems don’t capture the inputs required to reproduce or trace an artifact.
CI/CD ≠ SDLC: The external dependency trap
Worse, packaging steps often lose what little metadata the build process might have recorded.
The resulting artifacts lack details about the build itself; they’re bereft of the exact source state, compiler flags, a full dependency graph, and other essential metadata. Without access to this information, organizations cannot deterministically reproduce build artifacts or verify their provenance.
What’s needed is an approach to packaging software that creates and preserves these details at every stage of the SDLC. What’s needed, then, is a philosophical shift in packaging.
It isn’t just that modern applications tend to depend on external components outside developers’ control—it’s that modern software practices assume and reinforce this dependency. In other words, external dependencies are a feature, not a bug, of how we expect to build and ship software today.
Think about how we moved from static linking to dynamic linking, followed by—in the last 15-20 years—containers and VMs, which we mostly adopted to make dynamic linking viable for our runtime environments. Along the way, language-specific package managers helped establish the convention that dependency resolution could be decoupled from the OS and handled in each project’s own build or runtime context.
Then came microservices—independently deployed services that depend on each other, and are dependencies in their own right. The industry came full circle, with the unit of deployment itself becoming a unit of dependency.
With each of these shifts, the goal wasn’t to eliminate external dependencies but to contain them—i.e., to isolate software runtimes, manage conflicts, and simplify deployment. Over time, then, we’ve cemented external dependencies as core to modern software delivery, making them harder to track, audit, and control.
CI/CD ≠ Production: Blind spots in testing too
And testing is just as opaque. Applications pull in open-source and third-party dependencies, but these packages get tested under conditions that aren’t transparent and don’t necessarily correspond to those in production. A package might be tested by contributors who assume a specific dependency set, config, or runtime—but these assumptions are undocumented, untracked, and invisible to downstream consumers. Testing environments themselves bake in implicit assumptions about dependency resolution and runtime behavior—assumptions that don’t always map to real-world production environments.
These implicit dependencies and untracked assumptions lead to downstream failures, and most orgs have no deterministic way to validate that their software will behave as expected in production.
The common issue is a lack of control over external dependencies. Packages and libraries evolve outside an organization’s purview, and without a way to record exactly what was built, how, and with which dependencies, teams cannot make strong guarantees about reliability, security, or reproducibility.
This isn’t just a “process gap” or a “tooling gap—it’s a basic flaw in how software is packaged and consumed.
The Need for Nix
I'd been doing software build and release engineering for 30 years before discovering Nix … and that was when I realized I'd been doing it wrong that whole time. I see in Nix the promise of a universal building block for software across the entire SDLC, and my “I have a dream” speech is that one day nobody would think of releasing software to the public domain without also maintaining a Nix expression for building it in Nixpkgs.
Nix is more than just a package manager—it’s a declarative build system, a purely functional configuration language, and a framework for creating, managing, and maintaining reproducible environments.
Nix builds all built packages as immutable, input-addressed artifacts and keeps them in a single directory (/nix/store) so software versions always remain isolated and conflict-free. Unlike traditional, OS-based package managers, Nix builds packages from declarative definitions and installs them in isolated store paths.
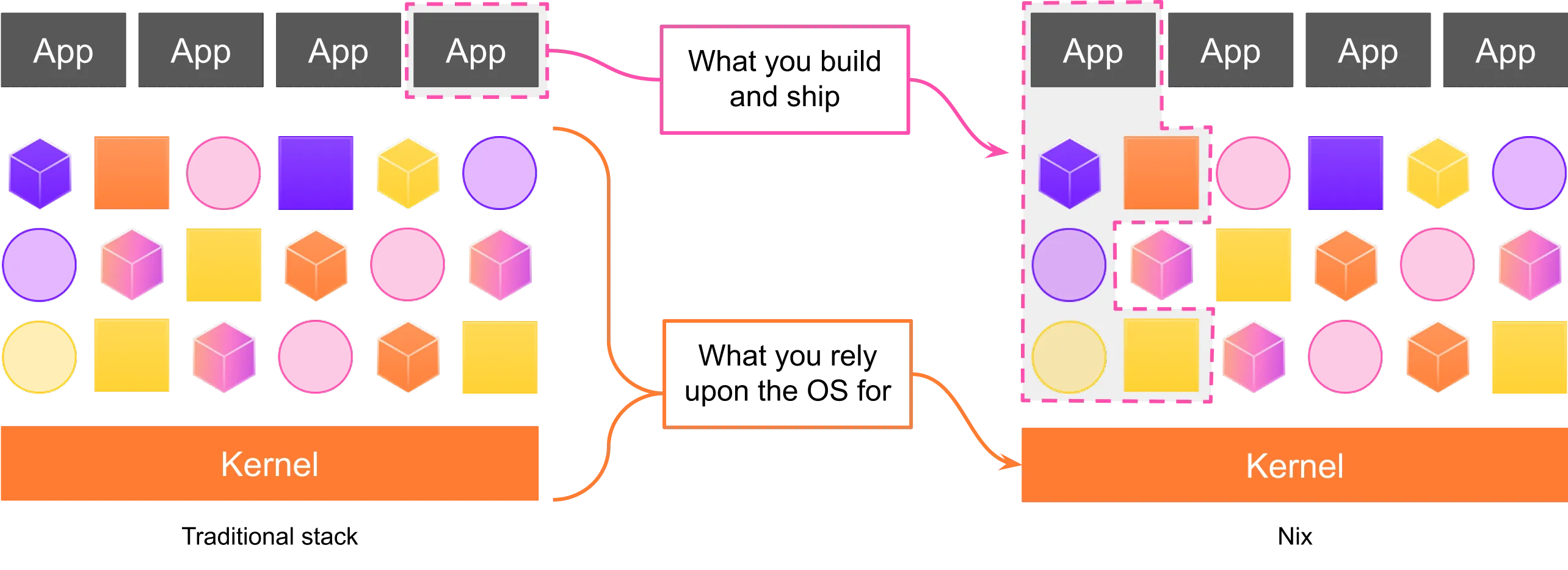
This has the following benefits:
- Installs are atomic and immutable. Rollbacks are reliable, upgrades don’t corrupt the system.
- Environments are isolated. Only declared dependencies get used, nothing leaks in from the host.
- Builds are sandboxed. They run in isolation, with access only to explicitly declared inputs.
- Conflicting versions of the same dependency can coexist. This doesn’t break the environment.
- Dependencies are explicitly defined and/or pinned. Builds are deterministic over space and time.
A Nix expression declaratively defines a build; when evaluated, it yields a derivation: a low-level, fully specified build plan. Nix expressions are architecture-neutral by design, so the same definition can often be reused to target multiple platforms—like x86-64 or ARM64—without modifying it. By supplying parameters like system or crossSystem during evaluation, you control which architecture the resulting derivation targets.
This lets teams build for multiple architectures without duct-taping together separate pipelines. They can create a single Nix expression that defines the build, and cross-compilation or native builds just work because dependencies are pinned and fully declared, not inherited from the host system’s state.
I’ve used the word “fundamental” a few times in this article. We all tend to overuse this word, but listen when I say: Nix fundamentally changes how we build, ship, deploy, and run software. Full stop.
But now let me tell you about Flox.
Bringing Nix to the SDLC
Flox builds on Nix, but it isn’t in any sense “a wrapper around Nix;” rather, it leverages Nix to solve intractable build and deployment headaches. Flox takes what’s inherently possible with Nix and makes it practicable, especially in the local context. Flox helps recast Nix as a pragmatic, end-to-end solution for managing runtime environments and software builds across the SDLC—from local dev, to testing, to prod.
We engineered Flox specifically to pick up where Nix leaves off. If you know and love Nix, you get that it’s the best, most pragmatic solution for building, shipping, and running software: i.e., for installing software and managing the SDLC. You’ve almost certainly tried to get your team or org to use it, too. With mixed results.
My own experience is that Nix by itself is absolutely enough—for those who have time to invest in learning and occasionally wrestling with it. But just as an airtight legal contract designed to protect you from any conceivable risk is usually also unparseable to anyone who isn’t a lawyer, Nix has a similar issue: it’s the right tool, it just isn’t an especially accessible one.
We built Flox specifically to pick up where Nix leaves off. Flox is premised on four core pillars:
- A development environment should be usable out of the box.
- Teams should be able to share and reproduce environments reliably.
- Software should be compiled into packages that work across every phase of the SDLC.
- Teams should be able to build and test knowing that what they ship will work the same in CI and prod.
I love Nix. It is formidably powerful. You absolutely can use Nix to do all of these things. But Nix isn’t for everyone. Flox is. With its intuitive commands, git-like syntax, and familiar UX, Flox makes Nix more accessible—building on Nix’s declarative model and strict determinism, smoothing over its sharper edges.
The Flox difference
With Flox, activating a fully configured environment is just one command: flox activate.
Flox environments are isolated within the bounded context of a subshell. They inherit the user’s permissions and variables—unless overridden. You can define them declaratively using flox edit. Or you can modify them imperatively with commands like flox install. You can also use flox edit to set variables, define services, author automation logic, and set aliases and functions. All without ever modifying the host system.
Flox inherits Nix’s deterministic builds and binary caching, so Flox environments are always reproducible across systems. Every build result is stored in a path- and input-addressed binary cache, so if an artifact has already been built for a given architecture, it doesn’t need to be built again. For teams and DevOps engineers alike, this means fast spin-up times, fewer redundant builds, and identical build outputs across dev and prod.
Flox is based on Nix, so rollbacks follow directly from Nix’s functional model. Builds are treated as pure functions, their outputs stored immutably in the Nix store, which means changing dependencies in an environment involves flipping a symlink from one known-good state to another. Because packages aren’t actually overwritten, rollback doesn’t require rebuilding or redeploying—just selecting a different result. Multiple versions of the same package can coexist, reverting from one version to another is simple and safe.
Flox, like Nix, also makes it possible to generate an authoritative software bill of materials (SBOMs). Because every dependency is explicitly tracked, generating an SBOM isn’t an extra step—it’s built into the process. This means you get built-in traceability for security audits, compliance, and incident response.
Complexity is a choice
Dependency management today isn’t just fragmented and fragile—it’s leaky.
Nix stops this at the source. Instead of fighting (and losing) a battle against configuration drift, we declare environments in advance so drift can’t happen. Instead of treating build artifacts as mutable, Nix makes them fully defined, reproducible outputs—built from a declarative input graph, isolated from ambient system state, and addressed immutably. This means builds are byte-for-byte identical across dev, CI, and production.
This isn’t theoretical. Thousands of companies use Nix in production to isolate dependencies, deploy across software and hardware boundaries, and permit deterministic, reproducible builds. At D. E. Shaw, I led a team that used Nix to build deterministic environments for everything from from dev tools and CLI workflows to low-latency trading and research systems, where we needed full reproducibility and auditability.
In fact, Flox emerged out of this work. We engineered it to bring the core principles of Nix—purely declarative environments, deterministic builds, immutability, and dependency isolation—to the enterprise … without requiring a reset of our existing workflows.
Complexity is a choice. We can step back and ask: what if software environments were reproducible from the start? That’s the shift Nix makes possible, and Flox is building for the future instead of patching the past.