


Achieving Rapid CVE Remediation in an Era of Escalating Vulnerabilities
Even before Claude Mythos was announced, there were clear signs that the next era of CVEs would be found by AI models. Big Sleep found a zero-day vulnerability in SQLite, Microsoft Copilot found 20+ CVEs in bootloaders, and DARPA launched AIxCC to incentivize AI CVE discovery.
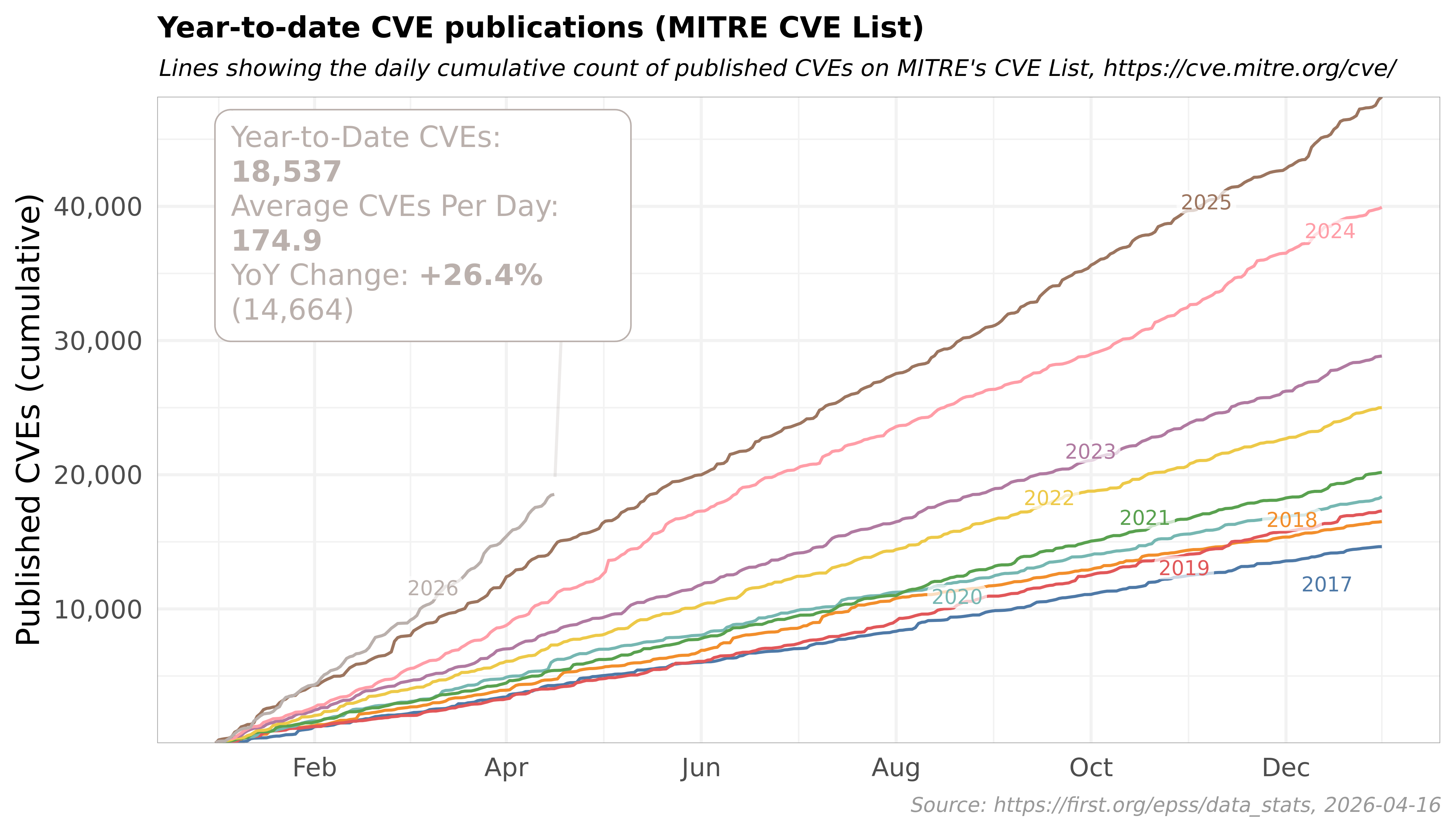
Now, with models like Claude Mythos emerging, there are two major takeaways: we'll see a rapid acceleration in the rate of CVEs as AI models improve, and we'll detect more CVEs that have persisted through versions, evading researchers for decades.
One of the trickiest categories is package CVEs. Most organizations don't have an up-to-date manifest of every package in their stack. System-level package managers like dnf, apt, and zypper, or toolchain package managers like pip, npm, and cargo, resolve package versions that vary across platforms, environments, and time. To feel confident that a vulnerable dependency isn't being used, organizations have to manually scan their entire stack. Couple that with ever-increasing number of CVEs, and the problem quickly becomes unmanageable.
This explosion of CVEs should encourage developers to embrace a system of record for their installed packages. It’s why we built Flox: an open source system for platform and devEx teams to centrally manage environments from development to production. Flox is made possible by Nix, a declarative package manager with a cryptographically verifiable dependency graph. Together, Flox and Nix flip the model: Instead of discovering vulnerable packages via after-the-fact scans, every dependency is verifiable at build time and can be traced by Flox’s system of record.
With traditional package managers, CVE triage scales with the number of artifacts, images, hosts, or runtime environments you run. If you have n deployments, you generally need to analyze each one, because there's no reliable way to prove two environments contain exactly the same dependencies.
In Big O terms, that's O(n) work, and most of it is redundant.
Nix changes what you analyze. Every Nix or Flox environment resolves to the complete, transitive set of packages and build inputs used to produce it. In the argot of Nix, this is called a "closure." Closures are input-addressed, so if two environments resolve to the same Nix store path, they can be treated as the same unit for CVE triage; you need not inspect both independently to prove that their dependency sets match.
This turns triage into a deduplication problem. If your n environments share only u distinct dependency sets, the expensive work (like checking which packages are affected or validating a patch) runs once per dependency set instead of once per environment. If for example 500 environments collapse to 50 unique dependency sets, then the triage work isn't "scan 500 things." It is more akin to:
- Map each environment to its dependency set.
- Group environments with the same dependency set.
- Analyze each unique dependency set once.
- Reuse the result for every environment in that group.
In Big O notation, the expensive analysis shifts from O(n) over 500 environments to O(u) over 50 unique dependency sets.
Plus, with Nix and Flox, the evidence teams require to address the two most work-intensive package-CVE questions is already captured in a lockfile and materialized in the resolved environment. To identify vulnerable environments, teams query which lockfiles, closures, or SBOMs contain the affected package, then map those records back to the environments that use them. To validate remediation, they compare the replacement graph and confirm that the vulnerable package is no longer present.
Compared with the status quo, the Nix/Flox workflow is lower-volume and lower-entropy: index the resolved records, query affected graphs, map them back to environments, edit the environment definition to select a patched package version, promote the replacement environment reference (a GitHub commit, a FloxHub generation), and compare the replacement graph against the vulnerable one.
Admittedly, this isn’t O(1). But—if we’re being honest—the Big O comparison isn’t apples-to-apples: the status quo is a time- and resource-intensive inspection workflow, while the Nix/Flox model reduces package-CVE triage to database lookups, graph comparisons, and atomic promotion of new environment references.
Non-determinism and CVEs.
There are several common sources of non-determinism. For some package managers (e.g., apt or dnf), the same install command can produce different results based on the environment it was run in, what mirror it was pulled from, what was cached, and when it was cached. Most package managers allow for version ranges, such that the specific package and its dependencies might resolve differently. The consequence? There’s no queryable record of the dependency graph across the stack.

What about lockfiles? Conventional lockfiles are useful because they reduce or eliminate resolver drift within a package ecosystem. A Cargo.lock, package-lock.json, or uv.lock can record what that ecosystem’s package manager selected. But a lockfile is not a declarative, deterministic description of the complete runtime environment: i.e., the base image, native libraries, tools, certificates, environment variables, and transitive dependencies that comprise the environment in which the application, service, or workload runs.
When a package CVE is disclosed, organizations often have to search across services, images, hosts, and runtime environments to determine their level of exposure. The vulnerable package might not be something that anyone (or any thing) intentionally installed; frequently, it’s a transitive dependency introduced by another package, base image, system library, or runtime-specific install step. This is the essential logic behind the class of transitive-dependency supply chain attacks we’ve seen.
In the conventional workflow, this is O(n) work: organizations must scan or analyze each artifact independently because there is no shared resolved dependency graph that proves which artifacts are equivalent. With Nix and Flox, teams can map each environment to its resolved dependency set—its closure—and group identical closures together. Again, this workflow still includes an O(n) inventory step, but the costly work shifts to O(u), where u is the number of unique closures.
In this workflow, determining exposure in the event of a CVE becomes a fast database query from affected package → affected closures, and from there to the environments that reference them.
Deduplicating CVE triage
When software is built from reproducible dependency sets, CVE triage no longer has to start by scanning each and every artifact independently. Instead, each runtime can be mapped to the resolved dependency sets from which it was built: its closure, package metadata, SBOM, or equivalent dependency record.
With a well-maintained dependency index, exposure queries can become fast lookups from CVE-affected package to affected dependency sets, and then from these sets to the environments that reference them.
How is Nix deterministic?
Nix achieves determinism by upending the conventional model we use to build, package, and consume software. Most package managers install prebuilt artifacts into a global, mutable system context, such that the final environment—the context in which the artifact runs—is determined by (a) the state of upstream repositories and mirrors, (b) the state of the host itself, and (c) all other ambient inputs.
Nix takes the opposite approach: it builds packages from declared inputs and persists them into immutable store paths. If a pre-built binary substitute is used from a cache, this still corresponds to a hashed Nix store path. That’s the key: Nix does not treat downloaded binaries as arbitrary packages; it treats them as the outputs of known build recipes with declared inputs.
This model makes the dependency graph queryable. Nix build outputs live in immutable store paths, and each output embeds its complete transitive dependency graph: the package, its dependencies, and the dependencies of those dependencies. (Again, this is its “closure.”) The resultant environment can be inspected, deduplicated, and reused for CVE triage, shifting the unit of analysis from “What happens to be installed on this host or image?” to “Which resolved dependency graphs contain vulnerable packages?”
Nix builds are hermetic in that they are isolated from the ambient state of the host. Given the same declared inputs, Nix reliably computes the same derivations and store paths. Nix outputs are verifiable, too. Every package in the Nix store is identifiable by a cryptographic hash based on its inputs.

You might be curious about the practical difference between Nix and Flox. Nix provides the package model, build system, and store semantics that make reproducible environments possible. Flox builds on Nix by turning those primitives into a complete software-lifecycle workflow for teams: creating environments, installing and updating packages, activating environments across machines, etc. The Flox CLI exposes familiar package manager commands like install, list, uninstall, and activate, so users can work with Nix without authoring Nix expressions or flakes. Flox also adds a curated catalog of packages, declarative environment manifests, and centralized, versioned sharing via FloxHub.
From manifests to resolved dependency graphs
A Flox manifest isn’t an install script: it’s a declarative description of an environment: the packages, variables, hooks, and services Flox will materialize at runtime. When Flox resolves that manifest, it writes the result to a file called manifest.lock. Think of this lockfile as a foundation for CVE triage: it records the package versions, source revisions, derivations, target systems, and Nix store outputs selected by the Flox resolver. These store outputs are the starting points for tracing the environment’s transitive dependency graph: resolved packages, their runtime dependencies, the dependencies of those dependencies. That graph can be inspected, indexed, scanned for CVE exposure, or used to create an SBOM.
For audit and CVE workflows, this gives teams something much stronger than an install script or an after-the-fact scanner result. The inventory step is still O(n): each environment has to be mapped to the resolved dependency record it is actually using, such as a manifest.lock, FloxHub generation, closure fingerprint, or SBOM. But that step is mostly bookkeeping. The costly work is in resolving the dependency graph underpinning those records—work that Nix and Flox do by default.
The remaining CVE-specific work is to (1) index those graphs against known vulnerability data, (2) deduplicate equivalent environments, and (3) validate whether a given CVE actually applies. Once environments are grouped by identical lockfiles or closures, that work shifts from O(n) over every environment to O(u) over the number of unique resolved dependency graphs. If 500 environments collapse to 50 unique lockfiles or closures, the expensive analysis runs 50 times rather than 500.
Remediation is deduplicated
The same model applies to remediation. FloxHub generates SBOMs for individual packages and complete environments, so organizations have a resolved dependency graph for each environment generation. When they index those SBOMs against vulnerability data, determining vulnerability exposure becomes a matter of querying a database: which resolved graphs contain the CVE-affected package, and which environments or FloxHub generations reference those graphs? Note: this is not unique to FloxHub in principle. Nix users can do the underlying work manually: Given a store output, they can traverse the closure, inspect the packages and libraries it contains, and generate an SBOM from that graph.
From there, teams update the relevant package or input, regenerate the lockfile, and (if using Flox and FloxHub) publish a new environment generation. The remediation question becomes quite concrete: does the new lockfile resolve to an updated version of the vulnerable package, and does the resulting dependency graph no longer include the vulnerable package output?
No, this isn’t O(1) remediation. Teams still need to test the runtime environment’s behavior, coordinate rollout, and promote the replacement FloxHub generation. But in this model you identify the affected graphs once, validate the replacement graph once, and promote that replacement wherever the vulnerable graph is used. This reuse applies to dependencies captured by the Flox/Nix environment; packages or artifacts fetched imperatively at activation or runtime must be pinned and tracked separately.
Because Flox and Nix guarantee reproducible outputs, fixing a CVE is as easy as locating the dependency in the manifest.lock, adjusting the manifest.toml and re-locking it, rebuilding, and then redeploying to any affected environments. Because the build is fully deterministic: if it works locally, it will work in production.
Why wasn’t this the norm?
Nix is a very different package manager from popular projects such as dnf, apt, brew, etc.
The main reason is a difference in values. Most package managers value convenience and fast build times. Nix values hermeticism, and hermeticism is fairly expensive. Everything is built in isolation; even with cached copies, that means longer build times and more disk space.
Today, we live in a different era. Disk space isn’t nearly as scarce, and we have ample Internet bandwidth. When compared to the needs of AI systems, Nix’s resource requirements are quite modest. The pendulum may shift from prioritizing efficient build times to prioritizing efficient remediation times, especially as AI agents drive up CVE volume.
We’re not unaware that many developers fear a package manager refactor. Thankfully, with coding agents, we believe the transition won't be nearly as daunting in the future, but we're still investigating the best paths for that approach.
Coding agents: the (sort-of) good and the (very) bad
The O(n) and O(u) comparison might appear trivial in a world of coding agents. We’re living in a time where Claude Code is running grep over hundreds of files to change the border-radius of a button.
At an infrastructure level, this plays out a bit differently. Yes, an organization can build an agent that routinely inspects codebases, collects dependencies, and compares them to emerging CVEs. As models get smarter, the O(n) scanning problem might disappear amongst the coding agent chaos. This is, however, a shortsighted way of thinking about the problem. For an AI agent to accomplish autonomous scanning, it'll need to access every single node, operate without error, and run hundreds of searches for every CVE. It might be able to do it routinely without error, but it is another “close enough” excuse in lieu of good security. Meanwhile, with Flox, there’s a single source of truth that agents can easily process.
Coding agents also raise their own counterpoint. Today’s ultra powerful agents aren’t just restricted to good actors. Attackers can quickly feed a coding agent a CVE and, with some clever prompting to evade guardrails, engineer a scalable attack. The zero-day nature of CVEs is truly becoming zero-day. And in an era of information density, a well-motivated actor might hone an attack on an organization's public disclosures like a conference talk that revealed the underlying packages in their stack.
It’s a morbid flywheel: AI agents can find flaws and scale exploits just as quickly as agents can manually scan codebases and push patches.
A closing thought: the new era
We hope that this article provides insight on why we have lent years of contributions to the Nix universe. Our hope is to make a compelling case for deterministic package management and a system of record ahead of the upcoming tidal wave of CVEs. In an era of nonstop automation, we believe that good security is going to matter more than ever.
In the last year, more has changed in software development than ever before. Our approach to package management should be one of those.